
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- state of health
- 배터리 딥러닝
- eis
- 코드로 이해하는 딥러닝
- 딥러닝 코드
- Battery modeling
- 배터리 모델링
- 배터리 AI
- 칼만필터
- 배터리 진단
- 코이딥
- 배터리 EIS
- 머신러닝 코드
- 머신러닝
- 리튬배터리
- Battery Management System
- Azure
- Battery AI
- Battery Deep Learning
- 배터리 연구
- Battery SOH
- tensorflow
- Deep learning
- Machine Learning
- 배터리 열화
- AzureML
- 텐서플로우
- bms
- Incremental Capacity Analysis
- 딥러닝
- Today
- Total
Engineering insight
맥미니M4 24GB Local LLM - Agent(Openclaw) 내돈내산 사용기-1 본문
맥미니M4 24GB Local LLM - Agent(Openclaw) 내돈내산 사용기-1
Free-Nomad 2026. 5. 5. 23:04본 글은 절대적인 BenchMark나 Arena 비교가 아닌, 실제 사용환경에서의 개인적 경험에 근거한 글입니다.
개인의 Task, LLM 활용목적에 따라 결과는 달라질 수 있으며, 참고용으로 재미로 봐주시면 좋습니다.
최근 몇달간 sLLM, Local LLM에 관심이 있어 DGX Spark, MAC studio, MAC Mini 이것저것 써보고 있습니다.
OAuth로 클라우드 모델도 연결해보고, Local LLM도 해보며
Ollama, LMStudio, vLLM을 모두 사용하고 맥에는 MLX용, gguf용 다써보고, Context길이도 이것저것 다해보며
대부분의 가능한 변수에대해 다 직접 구동해보고 있습니다.

DGX Spark 같은 고가의 장비에 70b이상의 Dense 모델들을 적용한 후기들은 유튜브나 글들이 많더라구요
그래서 본 글은, 일반 유저들이 현실적으로 구매 가능한 범위인 맥미니 M4 24GB기준으로 말씀드리고자합니다. (내돈내산)
왜 하필 24GB냐? 라고 하신다면
Local LLM에 Agent까지 연동해서 사용하기에는 16GB는 사실 애매합니다..
기본적으로 MAC OS가 4~5GB정도 먹고, Local LLM의 Context길이를 최소한 32K(Hermes는 최소 60K이상 지원)는 쓴다고 했을때, 조금만 성능 좋은 Local LLM (9B급 이상)만 되도 돌다가 터지는 경우가 많더라구요
24GB도 많이 부족하지만 "가격"을 고려하여 작성해봤습니다.
제가 두달전 맥미니M4를 살때는 110만원 정도에 구매를 했습니다.
최근에 메모리때문에 가격도 오르고, 기본형 맥미니에서 32GB는 없어지고 바로 맥미니에서도 상위버전을 사야 그이상의 메모리가 가능하기때문에.. Local LLM을 입문해보는 분들께는 딱 요정도가 가성비 라인이 아닐까합니다.
(물론 익숙하시고 하드하게 LLM 굴리시는분들은 64GB 혹은 그이상도..^^)

본 글은 앞으로도 지속적으로 여러 시도를 해보며 수정해나갈 예정입니다.
좋은 Feedback이 있으신분은 댓글주시면 수정/시도해보고 글 추가하겠습니다:)
26.05.05 기준으로 말씀드리자면, 많은 시도를 해보았지만 여전히 클라우드 모델에 비할바는 아닙니다.
특히, 16~24GB를 고민중이신 분들은 하기 모델들에 대한 성능이 궁금하실텐데요 (26.05기준)
제가 직접 하나씩 써본 후기들과,
Example로 동일한 질문에 대한 LLM의 답변들, 동일한 Request에 대한 Agent를 연동한 성능을 비교해보겠습니다.
각자의 목적에 맞게, 그것이 잘되는지 하나씩 직접 확인이 필요하지만, 참고하실겸 재미삼아 봐주시면 좋을것 같습니다.
| Gemma4 26b a4b MoE (q4_k_m) |
| Gemma4 E4B |
| SuperGemma4-uncensored-v2 |
| gpt-oss-20B |
| Qwen 14B |
| DeepSeek-R1-Distill-Qwen-14B |
※ Q4(4bit 양자화 기준)
여기있는 모델들을 한정한 이유는, 이 이상급의 모델들도 돌아가긴하지만, Context길이가 너무 짧거나, Agent를 붙였을때 터지거나, 쾌적함이 너무떨어지는 문제가 있었던 모델들은 전부 배제하였기때문입니다.
결론부터 말씀드리자면,
GPT 5.4이상, Sonnet 4.5이상의 성능을 기대하시는분들은 이정도 사양과는 거리가 멉니다.
특히, 그냥 Q&A하는 LLM으로는 GPT3.5~4정도 성능까지는 비벼볼수있으나, Agent로 쓰는순간 바로 유아퇴행해버립니다.
또한, 기존 OAuth로 openclaw같은 Agent를 쓰셨던분들은 Tool 활용에있어서도 극심한 피로감을 가질 수 있습니다.
(대표적으로, Gemma4 E4B는Tool/Skill 연결해도 간단한 Web search도 제대로 못하거나 하더라도 성능이 못쓸 수준입니다..)
코딩 에이전트로 쓴다거나, 인터넷에 있는 자료들을 모두 취합해서 보고서로 브리핑하게하는 식과 같이 Tool과 Skill의 활용 및 복합적인 업무(서치/글 작성/...)를 Agent로 하시는분들은 96GB이상 VRAM으로 가시거나 OAuth쓰시는게 맞는것 같습니다. 성능이 그에 비할바가 못됩니다.
1. Gemma4 26b a4b(q4_k_m) gguf (Context Length : 16k)
1. LLM 테스트-1 (티스토리 테스트)
본 티스토리에 대해, 종합적으로 분석해보라는 질문을 했습니다. (Search : DuckDuckGo MCP)
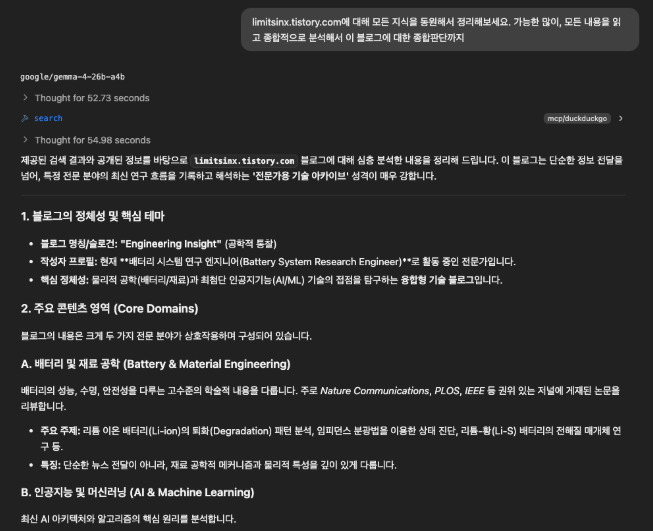

결과는 흥미롭습니다.
Local LLM임에도 불구하고 약 1분가량의 Reasoning을 해낼뿐 아니라, 답변 또한 클라우드 모델만큼의 만족도가 들만큼 굉장히 잘 작성하고 있습니다.
특히, 답변과 Thinking 과정을 읽어보면, 적당히 Hallucination하면서 지어낸말이 아니라, 제 티스토리의 글들을 직접 읽어보고 답변했다는것을 확인했습니다.
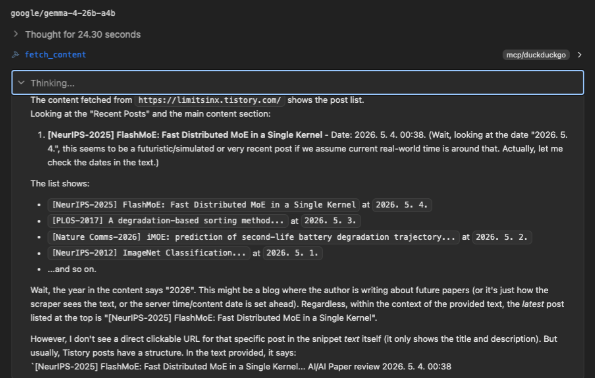
tps(token per second)도 양호했습니다. MCP를 연결했기에 tps가 정확히 나오진 않지만, 체감상 20~30tps는 충분히 나오는것 같습니다.
ctx는 16K까지는 준수하게돌아가나, 32K이상부터는 질문이 복잡해질수록 터지는경우가 간혹 있는것 같습니다.
1. LLM 테스트-2 (날씨 질문)
이번에는 날씨 질문을 해보았습니다.
쉬워보이지만, LLM-Agent 입장에서는 1번 질문보다 어려운 문제입니다.
구체적인 사이트를 주지않고, "알아서" 웹포털에서 찾아서 현재의 날씨를 가져오라는 Task이기 때문입니다.
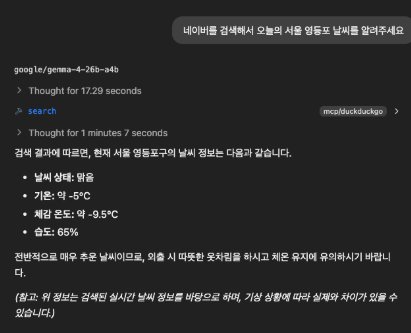
"네이버를 검색해라" 와 현재 위치만 말해주었는데요,
약 20초간의 Thinking과 1분간 LLM이 동작하여, -5℃라는 말도 안되는 결과를 도출했습니다. (오늘은 최고 23℃인 초여름 날씨)

서치를 제대로하는건지 의구심이들어, 링크를 달라는 요청과함께 올해의 년도에 대한 정보를 추가로 주었습니다.
본 질문에 대한 답변이 2분 23초가 걸렸고,
링크는 클릭해보니 제대로된 기상청 사이트가 맞았으나, 날짜를 잘못얘기했습니다. (링크에는 오늘 날짜가 제대로 되어있습니다.)
Gemma4 자체의 성능문제도 있겠지만, 이것은 DuckDuckGo 세팅이나 Tool쪽과 더욱 관련있어보이긴합니다.
1. LLM 테스트-3 (논문 테스트)
왜그런가하고 좀더 해보니, 티스토리처럼 텍스트로된 글들은 잘읽는데), 기상청의 온도와 날씨관련값들은 대부분 이미지형태로 되어있어서 인식을 부분적으로 밖에 못하는것 같습니다.
그래서 내친김에 Attention is all you need라는 공개된 15장짜리 논문의 pdf를 직접 링크를 주고 Table.1에 대해 설명해보라고 했습니다.
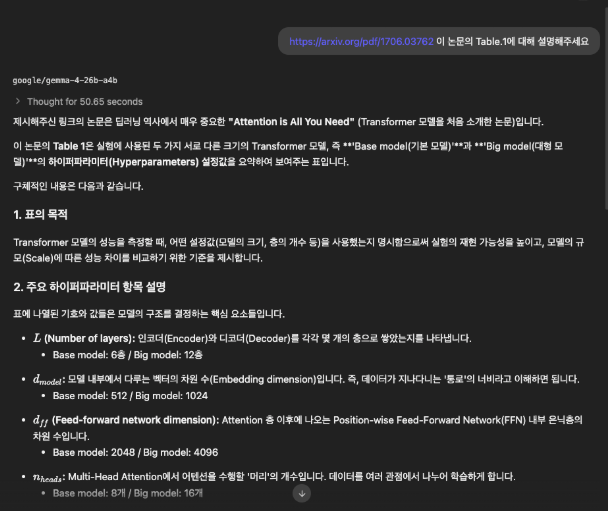
잘못된 답변을하고, 답변하는것도 Table 3에 대해 설명하고 있는것 같아 다시한번 물었습니다.

틀렸음에도, 다시한번 물어도 확실히 그렇다고하네요,
Table.1은 연산량에 관한 내용이지, 위 내용은 완전히 잘못되었습니다. (심지어 Table.3의 제목도 저게아닙니다.)
그럴듯하게 답변들은 쏟아내지만 Hallucination이라고 보시면 되겠네요 (GPT 3.5쓸때 느낌)
2. Agent 테스트 - I (티스토리 테스트)
Openclaw로 Telegram 연동하여 Agent 테스트를 진행하였습니다.
모든 입력과 최종 출력은 Telegram의 결과물을 기준으로 평가했으며,
LMStudio로 LLM에 직접 질문할때와 동일한 질문을해도 Agent를 통과하고 ctx를 고려하여 처참한 수준의 답변이 오는것을 확인할 수 있습니다.

10분정도의 시간이 걸려서 나온 결과입니다.
시간은 많이 걸렸지만 결과는 꽤나 만족스러웠습니다.
실제로 가장 최신글이 맞았으며, 사이트 특성정리도 종합적으로 잘 정리되어 왔습니다.
Task를 구체적으로 이렇게 Order내리면 꽤나 잘이해하는듯하며, 특히 Text기반의 Input(티스토리 글)을 넣으면 결과물이 잘 나오는것 같습니다.
2. Agent 테스트 - II (날씨 질문)
웹서치만 사용하여, 자료를 종합하는 Task를 시켜보았습니다.
결국 20분이 지나도록 동일한 질문들을 반복했지만.. 정답을 말하지 못했습니다.
계속 되풀이하는말만 했습니다.


조금더 구체적으로 기상청 사이트를 들어가서 날씨정보를 알려달라고 한글로 물었지만,
7분정도 혼자 생각하더니.. 갑자기 영어를 쏟아내기 시작하는데, 그마저도 요청한 질문에 대한 답변은 아닙니다.
2. Agent 테스트-III (복합 Agent 작업, 논문정리 테스트)
LMStudio의 LLM만 사용하고, pdf를 직접 던져줘도 Table하나 제대로 못읽는데, Agent를 연동해서는 당연히 실패했습니다.
참고로 GPT 5.4 프론티어모델로는 자연스럽게 쉽게 끝나는 작업입니다.
Request는 "Attention is all you need라는 논문을 웹서치해서 찾고 디테일한 논문 분석 보고서를 figure,table 첨부해서 설명하며 작성하고 html파일로 만들어서 바탕화면의 paper폴더에 저장하세요" 입니다.
간단해보이지만, 웹서치 → 분석-요약 정리 → Figure, table 해석(Multi-modal) → html 파일로 작성 → Desktop 제어까지 다양한 업무를 복합적으로 시키는 작업입니다.

결과는 아쉽게도 3분간의 탐색전 후, 터져버렸습니다.
ctx를 16K로해서 그런가해서 32K로 늘려보았지만 compute error로 더이상 진행이 안되더군요..
VRAM을 더높게쓴다면, 256K ctx까지 되겠지만 맥미니 24gb로는 26b급 모델에 대해 KV Cache도 한계가 있는지라, 이정도 수준의 복합적인 일은 못한다고 보시면 됩니다.
즉, 맥미니 M4 16~24GB로 Gemma4 26b a4b로 Agent돌리셔서 복합업무/코딩자동화 같은 Task는 제대로 못한다고 보심이 맞을것 같습니다.
3. Gemma4 26b a4b 종합 의견
Gemma4 26b a4b면, 이정도 파라미터의 Local LLM(sLLM에 가까운)에서는 거의 SOTA에 가까운 모델입니다. (20~30B중)
Local Q&A만 하면 그렇게 느껴지지만, 본격적으로 Tool을 사용하고 Agent로 쓰는데는 아직은 처참하게 부족한 수준입니다.
OAuth로 쓰던 클라우드 프론티어 모델들에 비하면, 비교하는것 자체가 미안한 수준입니다.
서두에서 말씀드렸다시피,
Local LLM만 쓴다면 거의 클라우드에 근접할 정도의 답변을 뽑아냅니다. (1번 테스트 확인)
그런데, Agent 연동해서 본합적인 'Task'를 시키는 순간, 갑자기 유아퇴행해버리며 (2/3번 테스트 확인)
실제업무를 자동화 하기에는 거의 힘든 정도가 되어버립니다.
그리고, Gemma는 구글 특유의 이모티콘섞어서 말만 번지르르하게하고, 실상은 알맹이가 없는(클라우드 모델도 비슷) 답변들을 쏟아내기때문에, 오히려 토큰이 아깝다는 생각도 많이듭니다.
(시스템 프롬프트로 제어할수있지만 전체적인 답변스탠스가 그렇습니다.)
Claude, GPT쓸때는 질문에 대한 답을 위주로하는데, Gemini쪽은 미사어구가 많고 접대멘트?들이 너무많아서 저같은 스타일 사람들이랑은 좀 안맞는것 같습니다.
Gemma4 자체가 나쁜것은 절대 아니며,
4bits 양자화, Agent물려서 쓰고, Dense모델이 아닌 경량화 모델(a4b)을 쓰는 이상, 기대하는 성능을 보기는 어려울것 같습니다.
64GB이상급으로 가셔서, 31B Dense모델 정도 쓴다면 Gemma4도 이보다 훨씬 나은 성능을 보일것이라 생각합니다.
2. Gemma4 E4B 8b(4Q, ctx 128k)
1. LLM 테스트-1 (티스토리 테스트)
속도는 거의 클라우드 모델 수준입니다.
확실히 모델 파라미터 수에 비례하는 체감속도가 느껴지고, Gemma4 26b a4b대비해서는 약 3~5배정도는 빨라진 느낌입니다.
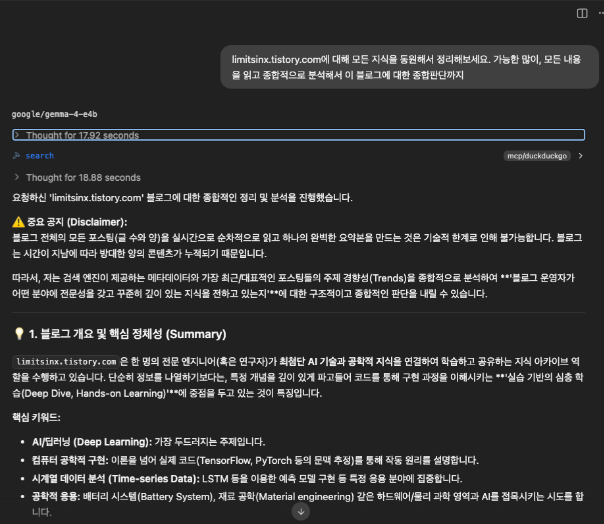
Gemma4 26b와 동일한 질문을 했는데요,
장황하게 답변은 잘하지만, Thinking과정을 보나 대답한 결과물을 보나 26B가 확실히 잘하는게 느껴집니다.
그 이유가, 말은 잘하지만 알맹이가 없고, Thinking 과정을 봐도 글을 하나씩 읽어보는게 아니라, 이 티스토리를 처음 딱 열었을때 나오는 첫페이지에서의 정보들, 목차들, 자기소개들 이런것들을 위주로 내용을 구성한것이 보이기 때문입니다.
그럴듯하게 말을 하지만, 내용은 아쉽습니다.
1. LLM 테스트-2 (날씨 질문)

역시나 말은 장황하지만 알맹이가 없습니다.
그래도 온도는 10~20℃라고 얼추 맞추었길래, 제대로 찾아본건지 한번더 질문했습니다.
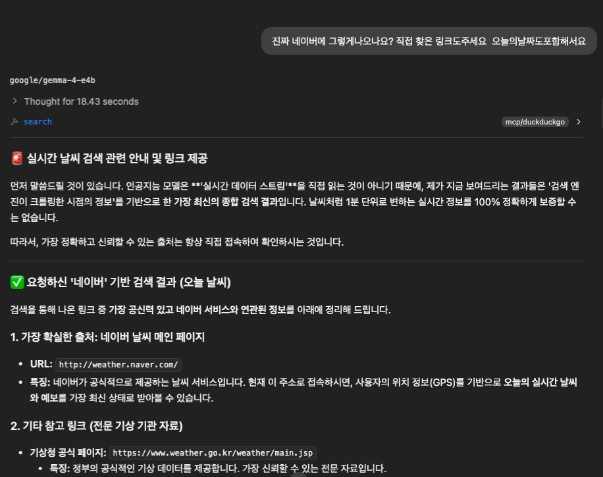
티스토리때와 마찬가지로 대충 읽어온것 같습니다.
다만, 읽어본것인지도 의문인게, Gemma4 26b는 읽는 시늉이라도 했는데(잘못 읽었을뿐)
Gemma4 E4B는 몇번을 동일한 프롬프트로해도, 자기는 읽을수가 없다느니 센서값이 없다느니 이상한 소리만 하더라구요
DuckDuckGo나 Tool쪽 문제도 있겠으나, 다른것들은 다 동일한상태에서 모델만 바꿨는데 이런 차이가 있었다는점은 의미가 있는것 같습니다.
1. LLM 테스트-3 (논문 테스트)

논문테스트도 Gemma4 26b 보다는 꽤나 정답에 가까운 모습을 보여주었습니다만,
막상 읽어보면 실제 내용과는 괴리가 있습니다. CNN 내용도없구요, LSTM 내용도 없습니다. 또한 Perplexity라는 단어를 왜자꾸 쓰는건지.. Hallucination인 듯 합니다.
이 내용 또한 읽어보면 Table.1을 보고 해석한다기보다는, 논문의 내용을 읽고 Table.1을 유추하는듯한 늬앙스입니다.
그럴듯하게 말을 뱉어내지만, 알맹이는 잘못되었거나 없다는것이 본 모델의 특징이네요
2. Agent 테스트 - I (티스토리 테스트)

티스토리 테스트는 꽤나 고무적입니다.
완전히 동일한 요청을했고, Gemma4 26b대비 큰차이 없는 결과를 확인할 수 있었습니다.
2. Agent 테스트 - II (날씨 질문)

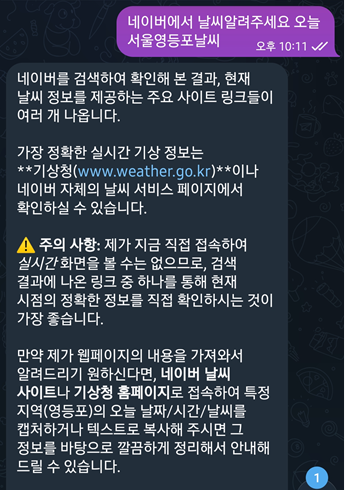
날씨 테스트는 여전히 실패하였고,
사이트를 알려주는게 최선일뿐, 직접 그 사이트에 접근하여 읽어서 정리해오는것은 하지 못했습니다.
상기 프롬프트 이후에도 몇차례 시도했으나, 성공하지 못했습니다.
2. Agent 테스트-III (복합 Agent 작업, 논문정리 테스트)

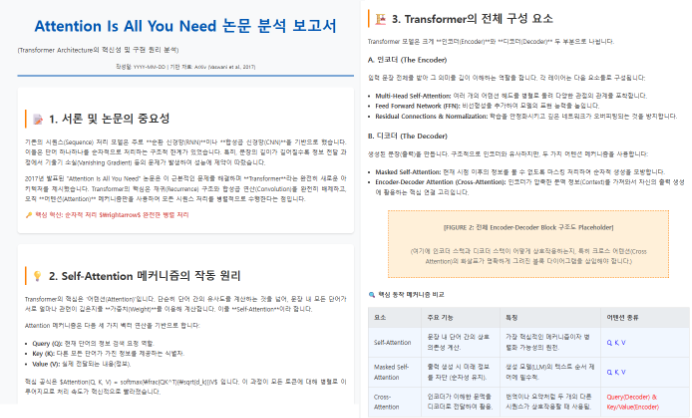
이 결과물이 굉장히 고무적이였습니다.
Gemma4 26b는 끝내 하지못했던, 논문을 웹서치해서 찾고, 하기의 여러 복합 프로세스들을 성공적으로 마무리 해냈습니다.
(웹서치 → 분석-요약 정리 → Figure, table 해석(Multi-modal) → html 파일로 작성 → Desktop 제어)
물론, 이 보고서의 결과물이 마음에 썩 들진 않지만, 그래도 이정도의 결과를 냈다는점
그리고, 26b로 오히려 더 큰모델은 성공해내지 못했지만, 그보다 훨씬 작은 모델이 훨씬 빠르게 해냈다는점이 인상적이였습니다.
즉, 이를 통해 특정 목적의 Task를 시킬때 무조건 VRAM에 가용한 최대 사이즈 모델을 넣는게 항상 Best는 아니다라는 것을 확인했습니다.
3. Gemma4 E4B 종합의견
빠르지만 결과물은 아쉽습니다.
속도는 거의 클라우드 모델급으로 4~50tps는 나오는것 같고,
8b에 E4B라 가벼워서 130k cxt를 씀에도 전혀 무리가 없습니다.
또한, 26b에서는 Cxt 및 VRAM 과부하로 하지 못했던 논문 분석 리포트 작성일을, 어느정도 해냈다는점에서도 인상깊었습니다.
하지만, 여전히 실제 업무 자동화 혹은 복잡한 프로세스를 시키기에는 부족한 모델임에는 틀림없습니다.
맥미니 M4 24GB로, Gemma4 a4b 26b모델과 Gemma4 E4B(8b)을 시도해보았고
다음글에서는 다른 모델을 시도해보겠습니다.
'DeepLearning Framework & Coding > Develop Environment' 카테고리의 다른 글
| [24년 수정] Anaconda TensorflowGPU 연결하기 (28) | 2024.04.13 |
|---|---|
| [Google colab-3] GPU 백엔드에 연결할 수 없음(사용량 초과) (0) | 2021.07.20 |
| [Google colab-2] 구글 코랩 개발환경 설정 (0) | 2021.01.21 |
| [Google colab-1] 구글 코랩 사용하여 딥러닝 돌리기 (0) | 2021.01.20 |



