
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 텐서플로우
- Azure
- Battery AI
- Deep learning
- 칼만필터
- bms
- AzureML
- 배터리 딥러닝
- Battery Deep Learning
- 배터리 EIS
- 머신러닝 코드
- Battery SOH
- state of health
- 리튬배터리
- 배터리 연구
- 코드로 이해하는 딥러닝
- 코이딥
- 배터리 열화
- 딥러닝 코드
- 딥러닝
- Battery Management System
- 배터리 진단
- Battery modeling
- eis
- 배터리 모델링
- tensorflow
- Incremental Capacity Analysis
- 머신러닝
- 배터리 AI
- Machine Learning
- Today
- Total
Engineering insight
[Microsoft AzureML - 10] 데이터 Feature Engineering 본문
[Microsoft AzureML - 10] 데이터 Feature Engineering
Free-Nomad 2021. 6. 26. 09:22※ 이전글
[Microsoft AzureML - 0] Intro https://limitsinx.tistory.com/113
[Microsoft AzureML - 1] 개발 환경 세팅 https://limitsinx.tistory.com/114
[Microsoft AzureML - 2] 학습할 데이터 불러오기 https://limitsinx.tistory.com/115
[Microsoft AzureML - 3] 데이터 전처리(Data pre-processing) - I https://limitsinx.tistory.com/116
[Microsoft AzureML - 4] 데이터 전처리(Data pre-processing) - II https://limitsinx.tistory.com/117
[Microsoft AzureML - 5] 학습모델 구현 및 검증 https://limitsinx.tistory.com/118
[Microsoft AzureML - 6] 여러 학습모델 동시에 성능비교 https://limitsinx.tistory.com/119
[Microsoft AzureML - 7] Binary Classification with Kaggle https://limitsinx.tistory.com/120
[Microsoft AzureML - 8] 모델 선정과 Hyper Parameter 자동튜닝 https://limitsinx.tistory.com/121
[Microsoft AzureML - 9] 학습데이터 CSV로 Export하기 https://limitsinx.tistory.com/122
Feature Engineering
제가 예전에 저의 현직 관련하여, 직무 홍보영상을 촬영한적이 있었습니다.
그때도 지금과 똑같이 언급했는데, 머신러닝에서 중요한건 "학습모델"보다 "양질의 수많은 데이터" 라고 생각합니다.
학습을 진행해보시면 아시겠지만, 학습모델을 변경해가면서 바뀌는 오차량보다 데이터 Column(Feature)을 어떤걸 선택하느냐에 따라 오차가 훨씬 변동폭이 큰것을 확인하실 수 있습니다.
이렇듯, 데이터 전처리단계에서 수많은 데이터들 중, 학습에 최적화된 결과값을 낼 수 있는 데이터들을 추려내는것을 "Feature Engineering"이라고 합니다.
빅데이터/통계하는분들은 EDA(Exploratory Data Analysis)라고 부르더라구요
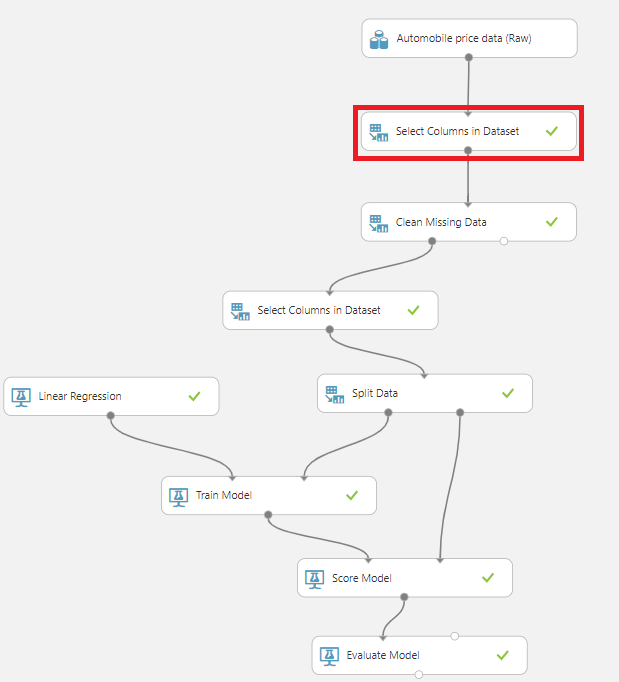
이제까지는 [Select Columns in Dataset]이라는 블록을 활용하여, 저희가 직접 어떤 Feature들을 사용할지 선택해주었는데요
하나하나 데이터들간의 상관관계를 보면서.. 이건 써야지..이건 안써야지..하면 만약 Feature가 수백개면 도저히 손으로는 할수가없겠죠??
이럴때 데이터들간의 상관관계를 수학적으로 계산하여 가장 높은것들부터 몇개만골라서 사용할 수 있는 블록이 있습니다.

[Data Transformation] -> [Feature Selection] -> [Filter Based Feature Selection]블록을 [Select Columns in Dataset] 블록자리에 넣어줍니다.
해당 블록은 "Filter"들을 기준으로, 여러가지 수학적 접근방식에 따라 Correlation(상관관계)를 계산하여 가장 상관성이 높다고 계산되는 Feature들부터 몇개 사용하겠다라는 것인데,
오른쪽에 property를 보시면 첫번째 Filter Scanning Method에서 "Filter"들을 골라줍니다.
각각의 방식들에 따라 Correlation을 계산해주는 방법이 다르기때문에 다른결과값들이 나올 수 있습니다.
그리고 밑에 Number of Feature는, 가장 상관성이 높은 Feature들 순으로 몇개를 학습에 쓸래??에 갯수를 넣어주는 공간입니다.
저는 Pearson Correlation으로 5개의 Feature를 뽑아내도록하여 학습을 진행해보겠습니다.

자동으로 Feature Engineering을 해주니, MAE가 2127이나오네요

제가 손으로 Feature들을 직접골라서 학습해주니, MAE가 1644가 나옵니다.
즉, 제가 손으로 골라 학습한게 훨씬 효율이 좋다는것이죠
이건, 단순히 수학적계산으로 상관관계를 파악하였기 때문에, 이 도메인에대해 사전지식이 있는사람이 고른 데이터대비해서 다른걸 골랐을 확률이 아주 높습니다.
이래서 빅데이터/머신러닝을 하는사람은 본인의 도메인을 가지고있어야하는게... 단순히 빅데이터상으로는 어느정도 관계가 있어보이지만, 실제 도메인에 지식이 있는사람 입장에서는 그건 그냥 당연한 물리적 결과일뿐 인과관계가 있다고 보긴어려울수도 있기때문이죠
정리하자면, Feature Engineering을 자동화하여 진행할수 있지만, 도메인에 지식이 있는사람의 경우라면 본인이 직접 Feature Selection을하는게 더욱 성능이 좋을수도 있습니다.
'DeepLearning Framework & Coding > Microsoft AzureML' 카테고리의 다른 글
| [Microsoft AzureML - 12] Train/Test 데이터 구분하기 (0) | 2021.06.28 |
|---|---|
| [Microsoft AzureML - 11] 이미지 데이터 학습 with Neural Network (0) | 2021.06.27 |
| [Microsoft AzureML - 9] 학습 데이터 CSV로 Export하기 (0) | 2021.06.25 |
| [Microsoft AzureML - 8] 모델 선정과 Hyper Parameter 자동튜닝 (0) | 2021.06.24 |
| [Microsoft AzureML - 7] Binary Classification with Kaggle (0) | 2021.06.23 |



