
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 텐서플로우
- 머신러닝 코드
- 딥러닝 코드
- 칼만필터
- Deep learning
- Battery SOH
- Battery modeling
- 배터리 열화
- tensorflow
- 배터리 AI
- 머신러닝
- 배터리 연구
- eis
- 코이딥
- Machine Learning
- 딥러닝
- 코드로 이해하는 딥러닝
- state of health
- Incremental Capacity Analysis
- bms
- Azure
- Battery Management System
- 배터리 딥러닝
- 배터리 모델링
- 배터리 EIS
- 리튬배터리
- 배터리 진단
- Battery AI
- AzureML
- Battery Deep Learning
- Today
- Total
Engineering insight
[Microsoft AzureML - 7] Binary Classification with Kaggle 본문
[Microsoft AzureML - 7] Binary Classification with Kaggle
Free-Nomad 2021. 6. 23. 22:38※ 이전글
[Microsoft AzureML - 0] Intro https://limitsinx.tistory.com/113
[Microsoft AzureML - 1] 개발 환경 세팅 https://limitsinx.tistory.com/114
[Microsoft AzureML - 2] 학습할 데이터 불러오기 https://limitsinx.tistory.com/115
[Microsoft AzureML - 3] 데이터 전처리(Data pre-processing) - I https://limitsinx.tistory.com/116
[Microsoft AzureML - 4] 데이터 전처리(Data pre-processing) - II https://limitsinx.tistory.com/117
[Microsoft AzureML - 5] 학습모델 구현 및 검증 https://limitsinx.tistory.com/118
[Microsoft AzureML - 6] 여러 학습모델 동시에 성능비교 https://limitsinx.tistory.com/119
Binary Classification
머신러닝에서 Supervised Learning은 크게 2가지로 나뉩니다.
예측을 위한 회귀분석과 분류를 위한 Classification인데요
Binary Classification이란 0 혹은 1로 판단할 수 있는 Yes or No문제에 많이 사용됩니다.
Kaggle의 데이터를 통해 이사람이 승진을 할 수 있을지?(1) 없을지?(0)를 판단하는 학습모델을 한번 구현해보도록 하겠습니다.
https://www.kaggle.com/arashnic/hr-ana
Kaggle HR Analytics train dataset은 상기 링크에서 받아주시면 됩니다.
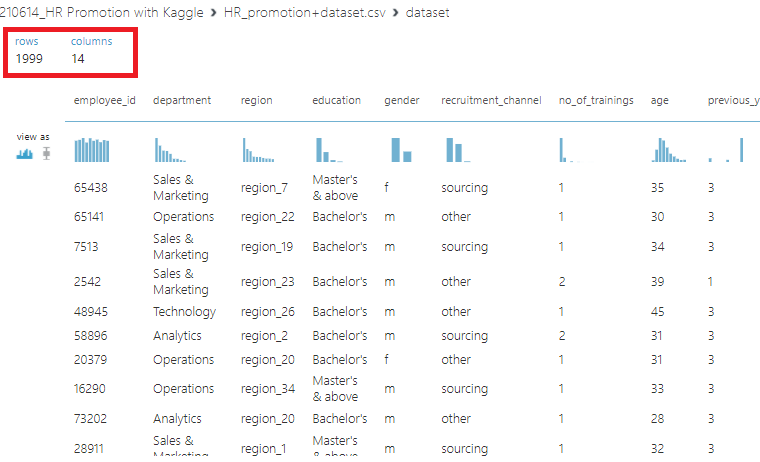
데이터를보니, 1999명의 회사원을 14개의 특징으로 묶어놓았네요
사번, 부서, 지역, 학위...와 같은 다양한 정보들이 있습니다.
여기서, 이사람이 승진을 할 수 있을지 없을지 AzureML로 블록코드를 하기와 같이 짜보았습니다.
※ 하기 Azure블록들을 짜는법은 이전글들에서 차례대로 정리해놓았기에 다시정리하진 않습니다.
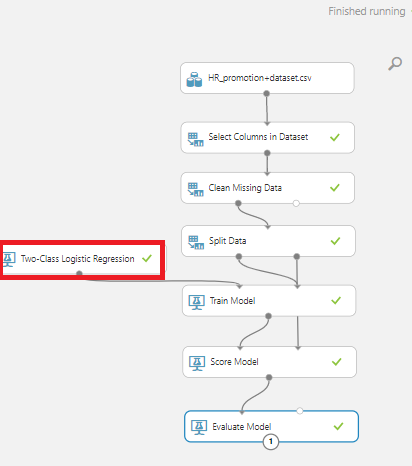
[Block 세부세팅]
- Select Columns in Dataset : 모든 column 사용
- Clean Missing Data : 전체 column중 행데이터가 한개라도 없는경우 행삭제(Remove entire row)
- Split Data : 트레이닝 70%, 검증 30%
- Train Model : Two-Class Logistic Regression : 이진분류를 하기위해 사용되는 Classification model 사용
이렇게 학습을 완료시켜주고, [Evaluate Model]의 [Visualize]를 하게되면 하기와 같은 이미지가 나오게 됩니다.

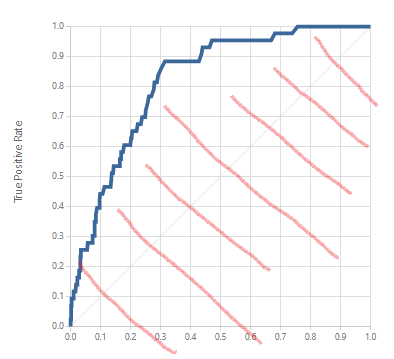
-ROC
ROC Curve란 Binary Classification의 성능을 한눈에 볼수있는 지표입니다.
상기의 활모양으로 그려진 파란색 커브가 ROC Curve인데요,
이 그래프를 읽고 해석하는방법에 대해 말씀드리겠습니다.

1. Threshold 관점에서 보는 ROC
Binary Classification에서 Threshold란 얼마만큼의 강도로 "Yes"를 이야기할꺼니~~입니다.
이게 무슨말이냐면,
Threshold값을 높게(1)잡으면, 왠만큼 "1"이라는 생각이 들어도 "1"이라고 말하지않으며
Threshold값을 낮게(0)잡으면, 진짜 조금만 "1"이라는 생각이들어도 바로 "1"이라고 말하는것입니다.
그래프의 y축을 보시면 "True Positive Rate" , x축을 보시면 "False Positive Rate"라고 적혀있는데요
통계학적용어로 이하 TPR, FPR이라 부르겠습니다.
TPR은 "실제로 1일때, 내가 한예측도 1일 확률" 이며, FPR은 "실제로 0일때, 내가 한예측이 1일확률" 입니다.
자세히보시면 왼쪽하단에 Threshold = 1인 원점(0,0)에서 TPR=FPR=0입니다.
즉, "실제로 1이여도 내가한예측이 1일확률은 0%다 = 실제로 1이여도 왠만해선 내가 1이라고 하지않는다" 라는 의미로
Threshold가 엄청 높게 잡혀있음을 알수있습니다.
반대로 좌표(1,1)지점은 TPR이 1로,
"실제로 1일때 내가 1이라고 예측할 확률이 100%다" = Threshold가 굉장히 낮다(0) 라는것을 해석해낼 수 있습니다.

따라서, 바로아래에 Threshold값을 변경할수있는 Scroll이 있는데요
Threshold = 0.5인값으로 Default로 나오지만, 이것을 바꾸어줄수 있습니다.
2. Precision과 Recall
해당 결과표를 보면 Precision = 0.75 / Recall = 0.07 이라고나와있습니다.
Precision과 Recall은 뭘까요??
한줄로 요약하자면
Recall = 실제로 "1" 일때, 내가 "1"이라고 예측할 확률
Precision = 내가 "1"이라고 예측했을때, 실제로 "1"일 확률
즉, Recall이 높다라는것은, 실제로 "1"일때, 내가 "1"이라고 예측할 확률이 높다
= Threshold가 낮아 실제로 "1"일때도, "1"이 아닐때도 내가 "1"이라고 말할 확률이 높다
= 정답이 Yes인 항목을 잘찾아낸다
But, 내가 Yes라고 말하는것이 정답일 확률은 낮다(대부분 Yes라고말할거니까)
반대로, Precision이 높다라는것은, 내가"1"이라고 예측했을때, 실제로"1"일 확률이 높다
=Threshold가 높아 내가"1"이라고 예측했을때는 왠만하면 실제로 "1"이다
= 정답이 Yes인 항목을 잘 못찾아낸다(1이라고 말을 잘안하니까)
But, 내가 Yes라고 말했다면 그것은 실제로도 1일확률이 높다.(아주 신중하게 1이라고 얘기하니까)
위의 문장들이 아주 중요합니다.
즉, Recall과 Precision은 Trade off관계라는 것이죠(항상 그렇진 않지만,대부분)
따라서 Precision과 Recall중 어디에 중점을 둔 결과값을 얻고싶은지에 따라 Threshold를 조정해서 모델을 사용하면 됩니다.
한번 바로 적용해보자면, Threshold를 기존 0.5에서 0.3으로 내려보겠습니다.
그럼 예상하기로는, Threshold가 낮아지니 "1"을 남발할 가능성이 높아지고, 이것은 실제로"1"일때만 "1"이라고 말하는 Precision이 낮아지는 결과를 초래하겠죠. 곧, Recall은 높게나올꺼구요


결과를 보시면, 저희가 예상한 그대로입니다 :)
Threshold를 0.5 -> 0.3으로 낮추니 Precision은 0.75 -> 0.57로 감소하였고, Recall은 0.07 -> 0.093으로 상승하였습니다.
3. Accuracy
해당 결과값의 Accuracy는 92%입니다.
92%의 정확도로 이사람이 승진할지 못할지를 구분한다?
상당히 높은적중률인데? 라고생각할 수 있지만, 전혀 아닙니다.
이게 바로 통계의 무서움인데요,
100명중 99명이 진급을 못하고, 1명만 진급을 하는상황이라고 가정해보시죠
그럼 제가 그냥 귀찮아서.. "100명다 진급못하는걸로 예측할께~~" 라고하면, 정확도(Accuracy)는 99%입니다..
1명만 진급한 상황을 제외하곤 모두 맞추었기 때문이죠
즉, "진급 못한사람(0)을 진급 못했다고(0) 맞추는것 보다, 진급 한사람(1)을 진급했다고(1)로 맞추는것에 더욱 가중치를 두어야 제대로된 확률이 맞다" 라는것입니다.
이것이 "Accuracy, 통계의 허와실" 입니다.
모르는사람은 눈뜨고 코베이는격이죠... 즉, Binary Classification에서 Accuracy는 그렇게 중요하다고 보기는 힘듭니다.
따라서, 2번의 Precision과 Recall을 보고 데이터를 평가하는것이 더욱 바람직할때도 있습니다.
4. AUC (Area Under Curve)

AUC는 ROC의 아래쪽부분 면적을 의미합니다.
AUC의 면적의 최대값은 무엇일까요?? 바로 1이죠 (변의길이가 1인 정사각형)

즉, ROC가 빨간색 선모양으로 나올때가 AUC=1일때 입니다.
그럼 이것은 무엇을 의미할까요??
좌표의 좌측상단을보면 TPR=1, FPR = 0인부분이 있죠
이말인 즉슨 "실제로 1일때 1이라고 예측할 확률 100% 이며, 0일때 1이라고 예측할 확률은 0% "
즉, 아주 이상적으로 모든케이스를 다 맞추는 정확도 100%의 상태라는것이죠
다시말하면, AUC=1이면 가장 이상적인 케이스로 Binary Classification을 perfect하게 하는경우이며, 클수록 좋다는 것입니다.

반대로 AUC = 0일때를 보시면 TPR=0일때 FPR=1 이죠
이말인 즉슨, 실제값이 "1"일때 내가 "1"이라고 예측할 확률 = 0% , 실제값이 0일때 내가 1이라고 예측할 확률 100%라는 의미입니다. 완전반대라는것이죠
즉, AUC가 클수록 값을 제대로 예측하고 있고, AUC가 작을수록 값을 반대로 예측하고 있다는거죠
그럼 여기서 Quiz
AUC = 0일때가 진짜 최악일까요?
정답은 "No"입니다.
왜요? 완전히 반대로 맞추는데요?
여기서 확률의 Entropy에 대한 개념이 필요한데요
쉽게얘기하자면, 모든걸 반대로 얘기하는 모델이 있으면, 그것의 반대로 내가 결과를 말하면 모두 맞는것 아닐까요??
진정한 최악의 결과는 AUC = 0.5일때입니다.
즉, O인지 X인지 완전히 랜덤하게 예측하는것과 동일한거죠. Entropy가 최대가 될때는 확률이 0%일때가아니라 50%일때입니다.
즉, AUC가 y=x형태로 그려질때 최악이라는 것입니다.

이번글에서는 Kaggle의 PR- Promotion(진급심사) 데이터를 통해
이사람이 진급할지 못할지에 대한 예측을 하는 모델을 구현해보았고,
통계적인 해석을 할 수 있는 방법에 대해 정리해보았습니다.
'DeepLearning Framework & Coding > Microsoft AzureML' 카테고리의 다른 글
| [Microsoft AzureML - 9] 학습 데이터 CSV로 Export하기 (0) | 2021.06.25 |
|---|---|
| [Microsoft AzureML - 8] 모델 선정과 Hyper Parameter 자동튜닝 (0) | 2021.06.24 |
| [Microsoft AzureML - 6] 여러 학습모델 동시에 성능비교 (0) | 2021.06.22 |
| [Microsoft AzureML - 5] 학습 모델 구현 및 검증 (0) | 2021.06.21 |
| [Microsoft AzureML - 4] 데이터 전처리(Data pre-processing) - II (0) | 2021.06.20 |



