
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 배터리 모델링
- Battery modeling
- 머신러닝 코드
- 딥러닝 코드
- 배터리 열화
- Battery SOH
- Battery Management System
- 리튬배터리
- state of health
- 텐서플로우
- bms
- 배터리 AI
- Incremental Capacity Analysis
- 배터리 연구
- Machine Learning
- Battery AI
- 칼만필터
- 딥러닝
- 머신러닝
- eis
- Deep learning
- 배터리 딥러닝
- AzureML
- 배터리 EIS
- Azure
- tensorflow
- 코이딥
- 배터리 진단
- Battery Deep Learning
- 코드로 이해하는 딥러닝
- Today
- Total
Engineering insight
[Microsoft AzureML - 8] 모델 선정과 Hyper Parameter 자동튜닝 본문
[Microsoft AzureML - 8] 모델 선정과 Hyper Parameter 자동튜닝
Free-Nomad 2021. 6. 24. 00:10※ 이전글
[Microsoft AzureML - 0] Intro https://limitsinx.tistory.com/113
[Microsoft AzureML - 1] 개발 환경 세팅 https://limitsinx.tistory.com/114
[Microsoft AzureML - 2] 학습할 데이터 불러오기 https://limitsinx.tistory.com/115
[Microsoft AzureML - 3] 데이터 전처리(Data pre-processing) - I https://limitsinx.tistory.com/116
[Microsoft AzureML - 4] 데이터 전처리(Data pre-processing) - II https://limitsinx.tistory.com/117
[Microsoft AzureML - 5] 학습모델 구현 및 검증 https://limitsinx.tistory.com/118
[Microsoft AzureML - 6] 여러 학습모델 동시에 성능비교 https://limitsinx.tistory.com/119
[Microsoft AzureML - 7] Binary Classification with Kaggle https://limitsinx.tistory.com/120
이번에는 모델의 선정과 HyperParameter를 자동으로 튜닝시키는 방법에 대해 알아보겠습니다.

이 전글에서 다루었던, HR Promotion의 Azure block diagram입니다.
Two-Class Logistic Regression을 학습모델로 사용했는데요
Regression이라는것은, 원인과 결과간에 어떤 "비례"하는 성질이 있을때 강력한 성능을 발휘합니다.
즉, y=x처럼 일차원적으로 어떤 상관관계가 있는 데이터들을 학습시킬때는 아주 효율적이라는것이죠
하지만, 이렇게 직접적인 "비례" 상관관계가 없는 데이터들 뭉텅이라면 성능이 아주 안좋아집니다..
y=ax+b라는 선으로 0과1이 구분될 수있도록 직선을 그어야하는데 그럴만한 참조인자가 없기때문이죠
이런경우를 위해, "비선형" 관계의 데이터에서 사용하기 위한 방법이 "Decision Forest" 방식입니다.

비선형성을 띄는 데이터속에서도 상관관계를 잘찾아내기때문에 대체적으로 Regression보다 성능이 좋습니다.
"그럼 Regression 대신 Decision Forest만 쓰면되는거 아니냐??"
Trade off로, 정확도나 포괄적인 범위의 데이터에서 사용할 수 있긴 하지만 엄청나게 복잡하고 계산이 느립니다.
또한, 강한 선형관계를 가지는 데이터들 사이에서는 Regression이 성능이 더 좋을때도 있습니다.


결과를 비교해보면, Regression이 성능이 더 좋습니다.

그런데 Binary Decision Forest의 Block을 클릭해보면 우측에 위와같은 Property들이 나오는데요
Resampling Method/Create trainer mode/ Number of Decision Trees....
숫자만 보면 8/32/128/1 이라는 파라미터들이 있는데, 이것을 "하이퍼 파라미터" 라고 부릅니다.
즉, 학습모델 내부에서 이런 하이퍼파라미터들을 어떻게 정해주느냐에 따라서도 학습의 정확도가 엄청나게 달라집니다.
"이 파라미터들을 하나하나씩 바꿔가며.. 결과값들을 비교해보면 됩니다..."
라고 하기에는 너무 비효율적이죠?
이런 Hyper Parameter들을 자동으로 찾아주는 Azure Block이 있습니다.

바로 [Tune Model HyperParameters]라는 Block 인데요
이 블록을 통해 하이퍼파라미터들이 오토튜닝 됩니다.
처음 블록을 꺼내면 빨간느낌표가 뜨는데, Output으로 어떤 column을 할지 세팅을 하라는것입니다.

[Launch Column Selector]에서 Selected Columns에 is_promoted를 추가해주면 됩니다.
(진급 가능할지 말지가 최종 Output Data니까..)

그다음, [Tune Model Hyperparameters] Block을 클릭해서 Property를 보게되면, 상기 이미지와 같이 나오는데요
여기서 Sweeping mode를 선택해주는데, 이것은 하이퍼파라미터들을 어떻게 넣어줄래?? 라는말입니다.
즉, Hyper Parameter를 한개씩 넣어가면서 어떤것이 최적화된 값인지 찾아가는게 Auto tuning의 방식인데
이렇게 한개씩 넣어가는 방법이 3가지가 있습니다.
1. Random Sweep
2. Random Grid
3. Entire Grid
1. Random Sweep

Random Sweep은, 원안에서 하이퍼파라미터를 선택해야한다고하면, 말그대로 무작위로 뽑아서 진행해보는것을 의미합니다.
2. Random Grid
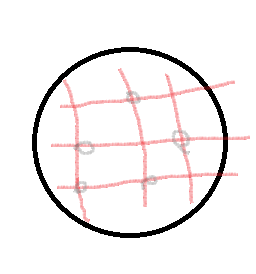
Random Grid는 원안에 Grid를 그리고, 일정간격을 두며 하이퍼파라미터를 선택하는 방식입니다.
Random Sweep과 비교해볼때 둘다 장단점이 있습니다.
Random Grid가 똑같은 반복을해도 조금더 다양한 종류의 Hyper Parameter들을 테스트해볼수 있는반면,
Grid위의 점들만 반드시지나기에 최적값이 그리드가 아닌지점에 존재하면 최적값을 찾을수가 없는거죠
3. Entire Grid

Entire Grid는 Grid상에 존재하는 모든점을 넣어 계산해보는것을 의미합니다.
따라서, Sweep방법은 이 3가지중에 선택을 해주면되는데, 저는 Random Sweep으로 한번해보겠습니다. :)

다음, Metric for measuring Performance인데요
이렇게 Sweep이든 Grid이든 방식을 통해 Hyper Parameter들을 바꿔갈때, 무슨값을 기준으로 바꿀래?? 라는뜻입니다.
즉, "정확도"를 기준으로 바꿀수도있고, "MAE"나 "RMSE"를 기준으로 바꿀수도있습니다.
Binary Classification이기에, 이전글에서 정리했듯 AUC를 기준으로 하이퍼파라미터 튜닝을 진행해보겠습니다.
(Regression인경우, 하단의 MAE나 RMSE를 선택해주시면 됩니다.)

그리고 마지막으로, 제일 중요한 "반복횟수" 입니다.
가능한 모든 하이퍼파라미터들을 넣으며 한개씩 비교해보는게 좋으나.. 그건 시간이 너무 오래걸리기 때문에
몇번정도 시도해볼까?? 라는것을 기입해주고 있습니다.

저는 5번정도로 돌려보도록 하겠습니다.

AUC가 0.844로, Hyper Parameter 튜닝없이 진행했을때 대비 약2%정도 성능이 향상되었고,
Recall은 0.256으로 확실히 성능이 좋아졌네요
어떤 하이퍼파라미터일때 최적값이 나왔는지는 하기 이미지의 노드를 [Visualize] 해주면 됩니다.


5번 반복수행한 결과, 2/945/14/14라는 Hyper Parameter를 가질때 AUC가 0.86으로 가장 높게 나오는것을 확인하실 수 있습니다 :)
반복횟수를 늘릴수록 보편적으로 더 높은 성능의 결과값이 나올것입니다.
'DeepLearning Framework & Coding > Microsoft AzureML' 카테고리의 다른 글
| [Microsoft AzureML - 10] 데이터 Feature Engineering (0) | 2021.06.26 |
|---|---|
| [Microsoft AzureML - 9] 학습 데이터 CSV로 Export하기 (0) | 2021.06.25 |
| [Microsoft AzureML - 7] Binary Classification with Kaggle (0) | 2021.06.23 |
| [Microsoft AzureML - 6] 여러 학습모델 동시에 성능비교 (0) | 2021.06.22 |
| [Microsoft AzureML - 5] 학습 모델 구현 및 검증 (0) | 2021.06.21 |



