 [코드로 이해하는 딥러닝 2-8] - Data Pre-processing
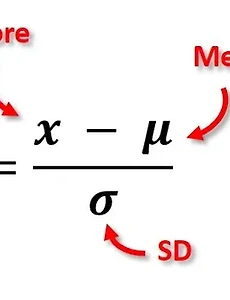
"Data Pre-Processing" 데이터 전처리(Data pre-processing)은, 머신러닝 및 빅데이터 분석가에게 아주 필요한 기술입니다. 데이터들의 범위는 중구난방이기 때문에 균일화를 해줄 필요가 있기 때문이죠 예를들면, 저는 [1,2,3] [1000,3,4], [10000,5,2] 라는 x_data를 학습시킨다고 가정해보죠 Feature 1은 1~10000의 범위를 갖는동안 나머지는 +-2정도의 값변화를 가지죠 즉, Feature들 간에 값의 scailing차이가 너무 나게되면, 한쪽으로 강한 Bias가 생긴 값들이 나올 수 있다는 것입니다. 따라서, 데이터를 학습시키기전에 전처리를 해주는 과정이 필요한데요 보통, Gaussian pdf를 따른다는 전제하에, Z-score (x-mean(..
2021. 1. 12.
[코드로 이해하는 딥러닝 2-8] - Data Pre-processing
"Data Pre-Processing" 데이터 전처리(Data pre-processing)은, 머신러닝 및 빅데이터 분석가에게 아주 필요한 기술입니다. 데이터들의 범위는 중구난방이기 때문에 균일화를 해줄 필요가 있기 때문이죠 예를들면, 저는 [1,2,3] [1000,3,4], [10000,5,2] 라는 x_data를 학습시킨다고 가정해보죠 Feature 1은 1~10000의 범위를 갖는동안 나머지는 +-2정도의 값변화를 가지죠 즉, Feature들 간에 값의 scailing차이가 너무 나게되면, 한쪽으로 강한 Bias가 생긴 값들이 나올 수 있다는 것입니다. 따라서, 데이터를 학습시키기전에 전처리를 해주는 과정이 필요한데요 보통, Gaussian pdf를 따른다는 전제하에, Z-score (x-mean(..
2021. 1. 12.




