
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 배터리 열화
- Incremental Capacity Analysis
- Battery AI
- eis
- 머신러닝
- 리튬배터리
- bms
- state of health
- tensorflow
- 배터리 진단
- 배터리 연구
- 배터리 EIS
- Battery SOH
- Azure
- 머신러닝 코드
- 배터리 딥러닝
- AzureML
- Deep learning
- Machine Learning
- 배터리 AI
- 코이딥
- 텐서플로우
- 칼만필터
- 코드로 이해하는 딥러닝
- 딥러닝 코드
- Battery Deep Learning
- 딥러닝
- Battery modeling
- Battery Management System
- 배터리 모델링
- Today
- Total
Engineering insight
[Nature-2025] DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning 본문
[Nature-2025] DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Free-Nomad 2026. 5. 16. 01:36DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
https://www.nature.com/articles/s41586-025-09422-z
DeepSeek-AI · arXiv 2501.12948 (2025/2026 versioned preprint) · PDF open access
dense summary
이 논문은 인간이 만든 CoT 정답 경로를 대량으로 모사시키지 않고도, 순수 reinforcement learning만으로 reasoning 능력이 emergent하게 생길 수 있다는 주장을 전면에 내세운 매우 영향력 큰 논문입니다.
가장 중요한 포인트는 base model에 바로 RL을 적용한 DeepSeek-R1-Zero가 자기검증, 재고, 긴 사고시간 증가 같은 reasoning behavior를 스스로 학습했다는 점이며, 이후 readability와 언어 혼합 문제를 보완한 multi-stage 파이프라인으로 DeepSeek-R1을 완성합니다.
핵심 알고리즘은 PPO보다 메모리/계산 오버헤드를 줄인 GRPO이며, value model 없이 group-relative advantage를 써서 긴 reasoning RL을 더 실용적으로 만들었다고 주장합니다.
논문의 진짜 의미는 단순히 DeepSeek 모델 하나가 잘 됐다는 것이 아니라, ★reasoning LLM post-training의 중심축이 SFT(Supevised-Finte Tuning) imitation → RL-based self-evolution 쪽으로 이동할 수 있음을 보여준 데 있습니다.
실무적으로는 reasoning model 개발에서 “좋은 CoT 데이터 많이 넣기”만이 답이 아니라, 검증 가능한 과제에서는 정답 기반 reward + 긴 rollout + 안정적인 RL 시스템이 더 강력한 경로가 될 수 있음을 시사합니다.
1. 왜 이 논문이 중요한가
최근 reasoning LLM 경쟁은 단순 benchmark 점수 경쟁이 아니라, 어떤 학습 메커니즘으로 긴 사고 과정이 생기느냐의 경쟁이기도 합니다. 기존 강한 접근은 보통 고품질 human-annotated CoT를 대량으로 넣고 그 패턴을 모사하게 만드는 것이었습니다. DeepSeek-R1은 여기서 한 걸음 더 가서, 적어도 수학/코딩처럼 정답 검증이 가능한 과제에서는, 사고 경로를 사람이 일일이 써주지 않아도 RL만으로 상당한 reasoning behavior가 emergent하게 만들어질 수 있다고 주장합니다. 이 주장이 맞다면, reasoning 모델 개발 비용 구조와 데이터 전략 자체가 바뀝니다.
2. 논문의 핵심 구성
2.1 DeepSeek-R1-Zero
가장 인상적인 부분은 DeepSeek-R1-Zero입니다. 이 모델은 conventional SFT warm-start 없이, DeepSeek-V3-Base 위에 바로 RL을 올립니다. reward는 최종 정답 정확도와 형식 준수 중심의 rule-based reward이며, 중간 reasoning 경로 자체는 사람 손으로 강하게 규정하지 않습니다. 그 결과 모델이 긴 답변을 쓰고, 스스로 검산하고, 경로를 다시 생각하는 행동을 자연스럽게 보입니다.
2.2 DeepSeek-R1
하지만 Zero에는 문제도 있었습니다. readability가 떨어지고, 영어/중국어가 섞이며, reasoning 밖 일반 도움말 능력은 제한적이었습니다. 그래서 최종 R1은 cold-start SFT → reasoning RL → rejection sampling/SFT → preference alignment RL 식의 다단계 파이프라인으로 만듭니다. 즉 논문 메시지는 “SFT 필요 없다”라기보다, reasoning core는 RL이 만들고, usable product quality는 그 위에 정렬 단계가 덧붙는다에 더 가깝습니다.
Figure 1 [원문 figure]

이 그림이 보여주는 것: DeepSeek-R1-Zero의 RL training 동안 AIME 성능과 평균 응답 길이가 함께 상승하는 모습을 보여줍니다.
핵심 해석: 성능 상승만 중요한 게 아니라, 모델이 스스로 더 긴 thinking time을 사용하게 된다는 점이 중요합니다. 저자들은 이것을 reasoning behavior의 자연발생 증거로 읽습니다. 즉 ★긴 CoT를 강제로 시킨 것이 아니라, RL 최적화 과정에서 모델이 더 길게 생각하는 편이 보상에 유리하다는 것을 스스로 배웠다는 것입니다.
왜 중요한가: reasoning capability를 단순 지식 회상과 구분하게 해주는 그림입니다. “답을 맞춘다”가 아니라 “어떻게 답을 맞추는 방향으로 내부 전략이 변하는가”를 보여줍니다.
Table 2 [원문 table]

이 표가 보여주는 것: 소위 “aha moment” 예시입니다. 모델이 수학 문제를 풀다가 스스로 ‘잠깐, 다시 생각해보자’ 식으로 경로를 수정하는 장면을 보여줍니다.
핵심 해석: 이 부분이 화제가 된 이유는, reasoning이 단순 정답회수나 template replay가 아니라, 적어도 표면적으로는 self-correction과 re-evaluation 형태를 띤다는 점 때문입니다. 물론 이것이 진짜 인간형 내적 사고를 의미한다고 단정하면 안 되지만, RL이 그런 출력 패턴을 강하게 incentivize했다는 것은 분명합니다.
의미: post-training reward 설계가 모델의 “생각하는 척”만이 아니라 실제 성능과 연결되는 재고 습관을 어느 정도 유도할 수 있음을 시사합니다.
3. 알고리즘 핵심: 왜 GRPO인가
이 논문에서 기술적으로 가장 중요한 기여 중 하나는 GRPO (Group Relative Policy Optimization)를 reasoning RL에 맞춰 전면에 세운 점입니다. PPO는 value model을 함께 학습해야 하고, 긴 CoT에서는 이 value estimation이 어렵고 메모리/계산 오버헤드도 큽니다. GRPO는 각 질문에 대해 여러 출력을 샘플링하고, 그 그룹 내부 reward의 상대 비교로 advantage를 계산합니다. 덕분에 별도 value model 없이도 policy optimization이 가능합니다.
쉽게말하면,
기존 PPO는 하나의 답변에 대해 평균적으로 얼마나 좋은 답변인것일까를 예측하지만,
GRPO는 한문제에 대해 답을 여러개 뽑아놓고, 그중 누가 상대적으로 잘했는지 비교해서 학습시키는 방식입니다.
Figure 3 [원문 figure]
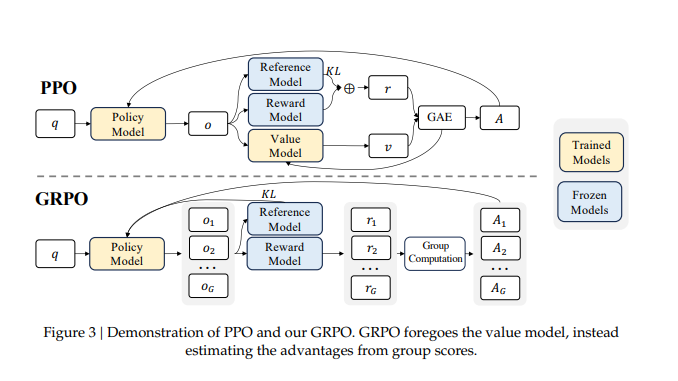
이 그림이 보여주는 것: PPO와 GRPO의 구조 차이를 도식화합니다. GRPO는 value model을 생략하고, 그룹 기반 score 비교로 advantage를 추정합니다.
핵심 해석: reasoning RL에서는 rollout이 길고 token budget이 매우 커집니다. 이때 value model까지 같이 들고 가면 메모리도 커지고 튜닝 난도도 오릅니다. GRPO는 그 부담을 줄여 실제 대형 reasoning model 학습에 더 실용적이라는 것이 저자들의 주장입니다.
중요성: 이 논문의 영향력은 모델 자체보다도, reasoning RL 인프라를 어떤 방식으로 현실화할 수 있느냐를 제시한 데 있습니다.
Figure 4 [원문 figure]

이 그림이 보여주는 것: MATH task에서 PPO와 GRPO 성능을 비교합니다.
핵심 해석: 저자들은 PPO도 잘 튜닝하면 근접할 수 있지만, λ 같은 하이퍼파라미터에 민감하고 추가 계산비용이 크다고 설명합니다. 반면 GRPO는 더 단순한 구조로 경쟁력 있는 결과를 낸다고 주장합니다.
실무 의미: reasoning model post-training에서 RL 알고리즘 선택은 단순 academic preference가 아니라, 실제 학습비용과 스케일 가능성을 좌우하는 문제입니다.
4. reward design에서 중요한 점
DeepSeek-R1-Zero의 초기 단계는 rule-based reward를 중심으로 갑니다. 정확도 보상과 format 보상을 섞고, 수학/코딩/논리처럼 정답 검증이 비교적 명확한 도메인에 초점을 둡니다. 여기서 중요한 메시지는, reasoning training에서 process reward model을 굳이 무겁게 만들지 않고도, outcome-verifiable task에서는 final-answer correctness만으로도 충분히 강한 학습 신호가 될 수 있다는 것입니다. 물론 이건 검증 가능한 과제에서 특히 잘 맞고, open-ended generation에는 그대로 일반화되기 어렵습니다.
5. multi-stage pipeline의 진짜 의미
많은 사람이 R1을 “순수 RL 승리”처럼 읽지만, 실제 완성형 DeepSeek-R1은 그렇지 않습니다. Zero가 reasoning kernel을 만들고, 그 위에 human-aligned cold-start data, rejection sampling, 추가 SFT, 그리고 preference alignment RL이 붙습니다. 즉 논문은 사실 RL-only discovery + alignment refinement의 결합이 현실적이라고 말합니다. 여기서 교훈은, emergent reasoning과 usable product quality는 동일 문제가 아니라는 것입니다.
Figure 2 [원문 figure]

이 그림이 보여주는 것: DeepSeek-R1의 multi-stage pipeline입니다. R1-Zero → cold-start data → RL → rejection sampling/SFT → second RL 식의 흐름이 제시됩니다.
핵심 해석: 이 그림은 논문의 진짜 메시지를 드러냅니다. 사람 데이터를 완전히 버린 게 아니라, reasoning 코어를 RL로 만든 뒤 제품 품질과 언어 일관성은 다시 정렬하는 구조입니다.
왜 중요한가: 많은 팀이 앞으로 reasoning model을 만들 때 pure SFT도 pure RL도 아닌, 이 하이브리드 post-training stack을 따라갈 가능성이 큽니다.
6. distilled models가 주는 함의
논문은 큰 reasoning model을 작은 모델들로 증류한 결과도 강조합니다. 이건 산업적으로 매우 중요합니다. reasoning을 잘하는 큰 teacher가 있으면, smaller dense/instruction model로 상당 부분 capability transfer가 가능하다는 뜻이기 때문입니다. 즉 frontier reasoning model은 직접 배포용뿐 아니라, 하위 모델군 성능을 끌어올리는 증류 인프라 역할을 합니다.
7. 실무적으로 무엇이 바뀌나
- 데이터 전략: 모든 reasoning 데이터를 인간이 직접 쓰는 접근의 상대적 매력이 줄어듭니다.
- 과제 선택: 정답 검증이 가능한 수학/코딩/STEM 과제가 RL bootstrapping에 특히 중요해집니다.
- 인프라 경쟁: 긴 rollout, 안정적 sampling, distributed RL infrastructure가 핵심 자산이 됩니다.
- 제품 전략: raw reasoning emergence와 user-facing readability/alignment는 분리해서 다뤄야 합니다.
8. 이 논문의 한계
- 자기검증처럼 보이는 출력이 진짜 내부 reasoning quality 향상인지, 혹은 보상에 맞춘 표면 패턴인지 완전히 분리하기 어렵습니다.
- rule-based reward가 잘 먹히는 도메인은 주로 verifiable task이며, 개방형 문제로 갈수록 같은 전략이 약해질 수 있습니다.
- 논문은 강한 성과를 보이지만, 재현성·compute budget·데이터 필터링 세부 구현에 따라 차이가 클 가능성이 큽니다.
- Reasoning quality와 안전성/정확성/과신 억제를 동시에 잡는 문제는 여전히 남아 있습니다.
9. 최종 요약
One-line core: 이 논문은 LLM reasoning을 인간 CoT 모방만으로 키우는 대신, 검증 가능한 과제에서 RL을 통해 self-evolving reasoning behavior를 만들 수 있다고 보여준 전환점 논문입니다.
Novelty: DeepSeek-R1-Zero의 RL-only emergence, 그리고 value model 없이 긴 reasoning RL을 실용화하려는 GRPO 설계가 핵심입니다.
Practical takeaways: 앞으로 reasoning model 개발은 SFT imitation만이 아니라, verifiable reward·long rollout·RL infrastructure·distillation을 함께 갖춘 hybrid stack 경쟁이 될 가능성이 큽니다.
Main limitations: open-ended reasoning 일반화, 표면적 self-correction과 진짜 reasoning 향상 구분, alignment와 safety 동시 최적화는 여전히 남아 있습니다.
Evidence links
- ArXiv abs: https://arxiv.org/abs/2501.12948
- PDF: https://arxiv.org/pdf/2501.12948.pdf
이 논문 핵심은 reasoning 능력을 인간 CoT 모방 없이 RL로 키울 수 있다는 것입니다.
특히 DeepSeek-R1-Zero는 SFT 없이 RL만으로 자기검증, 재고, 긴 사고흐름 같은 reasoning behavior를 스스로 학습합니다.
그 뒤 readability/언어혼합 문제를 고치기 위해 cold-start data, RL, rejection sampling, SFT를 섞은 multi-stage pipeline으로 DeepSeek-R1을 만듭니다.
알고리즘적으로는 PPO보다 가벼운 GRPO를 써서, value model 없이 group-relative advantage로 긴 reasoning RL을 돌립니다.
논문의 진짜 의미는 “좋은 CoT를 많이 가르친다”에서 “검증 가능한 문제에선 RL로 reasoning을 emergent하게 키운다”로 축이 이동했다는 점입니다.
한 줄로 요약하면 R1은 reasoning LLM의 post-training 패러다임을 imitation 중심에서 RL 중심으로 밀어올린 논문입니다.



