
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- bms
- Azure
- 딥러닝
- 배터리 딥러닝
- AzureML
- Battery Management System
- eis
- Battery AI
- state of health
- Battery Deep Learning
- 배터리 연구
- 배터리 모델링
- 텐서플로우
- 배터리 진단
- 배터리 AI
- 칼만필터
- tensorflow
- 머신러닝
- 코이딥
- 배터리 EIS
- 리튬배터리
- 머신러닝 코드
- Deep learning
- 딥러닝 코드
- 코드로 이해하는 딥러닝
- 배터리 열화
- Incremental Capacity Analysis
- Machine Learning
- Battery modeling
- Battery SOH
- Today
- Total
Engineering insight
[arXiv-2026] FlashMoE: Reducing SSD I/O Bottlenecks via ML-Based Cache Replacement for Mixture-of-Experts Inference on Edge Devices 본문
[arXiv-2026] FlashMoE: Reducing SSD I/O Bottlenecks via ML-Based Cache Replacement for Mixture-of-Experts Inference on Edge Devices
Free-Nomad 2026. 5. 5. 23:39FlashMoE: Reducing SSD I/O Bottlenecks via ML-Based Cache Replacement for Mixture-of-Experts Inference on Edge Devices
FlashMoE: Reducing SSD I/O Bottlenecks via ML-Based Cache Replacement for Mixture-of-Experts Inference on Edge Devices
FlashMoE: Reducing SSD I/O Bottlenecks via ML-Based Cache Replacement for Mixture-of-Experts Inference on Edge Devices Byeongju Kim Jungwan Lee Donghyeon Han Hoi-Jun Yoo Sangyeob Kim Abstract. Recently, Mixture-o
arxiv.org
이 논문은 메모리 제약이 큰 엣지/로컬 장치에서 대형 MoE 모델을 돌릴 때 병목이 되는 것은 단순 파라미터 수가 아니라 SSD에서 expert를 얼마나 자주 다시 읽어오느냐라는 점을 전면에 놓고, ML 기반 cache replacement로 SSD I/O를 줄여 실제 추론 속도를 높인 시스템 논문입니다.
1. 문제 정의
MoE 모델은 total parameter는 매우 크지만 한 번에 일부 expert만 활성화되므로, 이론상 로컬 장치에서도 inference 가능성이 있습니다. 문제는 실제 구현입니다. VRAM이나 DRAM에 모든 expert를 둘 수 없으면 inactive expert를 SSD에 내려야 하는데, 이때 SSD 재로딩이 잦아지면 latency가 급격히 커집니다.(본 논문의 문제의식) 기존 offloading 시스템은 주로 DRAM 기반을 전제로 했고, 메모리가 작은 on-device 환경에서는 현실성이 떨어졌습니다.
이 논문은 질문을 명확히 바꿉니다. “MoE를 edge device에서 돌릴 때 진짜 병목은 expert sparsity가 아니라 SSD I/O와 cache eviction인가?” 그리고 그 병목을 heuristics가 아니라 학습 기반 정책으로 줄일 수 있는가를 묻습니다.
2. 기존 한계
- 기존 MoE inference 시스템(Fiddler, DAOP 등)은 inactive expert를 DRAM에 두는 RAM-offloading 전제가 강했습니다.
- 이 전제는 16~64GB 정도의 user-grade machine에서는 쉽게 무너집니다.
- LRU/LFU 같은 단순 cache replacement는 expert routing의 특수한 재사용 패턴을 잘 반영하지 못합니다.
- 결과적으로 evict하면 안 되는 hot expert를 빼고, 곧 다시 SSD에서 읽어와야 하는 비효율이 생깁니다.
3. 이 논문의 정확한 novelty
이 논문은 MoE edge inference의 병목을 memory capacity 자체보다 expert cache policy와 SSD I/O 문제로 재정의합니다. 그리고 LRU/LFU 같은 규칙기반 정책 대신, recency + frequency를 학습적으로 결합하는 FFN cache policy를 도입해 expert eviction을 더 잘 결정합니다.
4. 방법 구조
- Model decomposition: experts와 non-experts를 분리 저장하고, expert는 layer/expert index 단위로 세분화해 on-demand loading 가능하게 구성
- Prefill stage: 한 batch에서 필요한 expert만 골라 SSD에서 1회 로딩 후 여러 token에 재사용
- Decoding stage: layer별 fixed-size expert cache를 두고 eviction policy를 적용
- ML-based cache: recency score와 frequency score를 정규화해 FFN에 입력, eviction score를 예측
즉 단순 운영체제 캐시가 아니라, expert routing pattern에 특화된 예측형 cache manager를 설계한 것입니다.
Figure 1 — MoE decoder layer에서 왜 expert cache가 핵심이 되는가

무엇을 보여주나: MoE decoder layer에서 gate가 token마다 top-k expert를 선택하고, 일부 expert만 활성화되는 sparse execution 구조를 설명합니다.
왜 중요한가: 이 구조 덕분에 total parameter는 커도 compute는 줄일 수 있지만, 반대로 말하면 필요한 expert만 계속 꺼내오는 memory hierarchy 문제가 생깁니다.
핵심 해석: 이 논문은 바로 그 점, 즉 MoE의 장점인 sparse activation이 동시에 SSD offloading 병목을 만든다는 점에서 출발합니다.
Figure 2 — LRU와 Belady 비교: 왜 단순 cache policy가 모자란가

무엇을 보여주나: expert routing heatmap 위에서 LRU와 Belady의 eviction timing 차이를 비교합니다.
왜 중요한가: LRU는 recency만 보기 때문에, 곧 다시 쓸 hot expert를 잘못 evict하는 문제가 있습니다.
핵심 해석: 논문은 이를 Eviction Delay / Evicting Hot Experts 문제로 정리합니다. 즉 SSD I/O 증가의 원인이 단순히 SSD가 느려서가 아니라 틀린 eviction decision 때문이라는 점을 보여줍니다.
Figure 3 — FlashMoE 전체 시스템 구조

무엇을 보여주나: FlashMoE 전체 architecture와 prefill process를 정리합니다. non-expert를 먼저 올리고, expert는 SSD에서 on-demand loading하는 흐름입니다.
왜 중요한가: 이 논문이 단순 cache 아이디어 메모가 아니라 실제 system design 논문이라는 점을 보여줍니다.
핵심 해석: FlashMoE는 모델 파일 구조 자체를 experts / non-experts로 분해해 initialization latency와 memory footprint를 동시에 줄입니다.
Figure 4 & 5 — ML-based cache 학습과 decoding pipeline
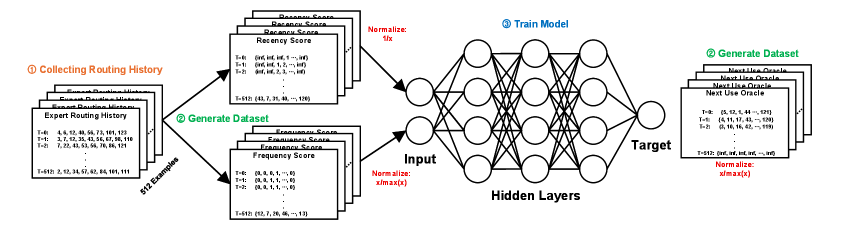

무엇을 보여주나: FFN 기반 eviction model의 학습 구조와 decoder layer pipeline을 제시합니다.
왜 중요한가: FlashMoE의 본질은 heuristic tuning이 아니라, recency / frequency를 합친 학습 기반 cache policy에 있습니다.
핵심 해석: SSD load가 decoding latency의 70% 이상을 차지할 수 있으므로, cache hit rate 향상은 곧 end-to-end latency 감소로 이어집니다.
★★★ 5. 입력 / 출력 / 계산 논리
입력은 현재 시점에서 각 expert의 recency score와 frequency score입니다. 논문은 recency를 1/r_t 형태로 정규화하고, frequency는 max(f)로 나눠 정규화합니다. 이 둘을 concat해서 FFN에 넣고 eviction score를 예측합니다.
- recency가 작을수록(최근 접근일수록) 재사용 가능성이 높음
- frequency가 높을수록 자주 쓰이는 expert일 가능성이 높음
- FFN은 두 정보를 같이 보고 “누굴 빼야 덜 후회할지” 예측
이 논문의 ML은 model output quality를 직접 예측하는 게 아니라, system cache policy decision를 예측하는 데 쓰입니다. 이 점이 꽤 신선합니다.
즉, LLM 외에 SSD I/O Latency 개선을 위해, 지워야할것/지우지말아야할것에 대한 판단을 하는 간단한 MLP를 학습하는 개념입니다.
6. 핵심 결과 수치
- cache hit rate: 기존 LRU/LFU 대비 최대 51% 개선
- overall inference speed: 기존 MoE inference systems 대비 최대 2.6× speedup
- 논문 본문 기준 LRU는 Belady 대비 약 73% vs 86% hit-rate 수준 예시가 제시됨
- LRU evicted experts의 34.2%가 5 step 내 재사용, Belady는 0.1% 수준
이 숫자들의 핵심은 “조금 빨라졌다”가 아니라, cache decision quality가 SSD I/O를 실질적으로 좌우한다는 점입니다.
7. 한계
- 논문은 FlashMoE 자체 구현 시스템의 성능을 보여주지만, 일반 공개 inference stack에서 동일 성능이 바로 재현된다는 보장은 없습니다.
- 사용 플랫폼이 user-grade desktop이지만, Mac mini M4 24GB와 동일한 소프트웨어/하드웨어 스택은 아닙니다.
- MoE의 다른 병목(KV cache, tokenizer, backend 최적화)은 이 논문 바깥 문제입니다.
- 모델 품질 문제가 아니라 시스템 최적화 논문이므로, “어떤 모델이 더 똑똑한가”를 직접 말해주진 않습니다.
Final Summary
핵심 한 줄
FlashMoE는 대형 MoE를 엣지 장치에서 돌릴 때 성능 병목이 단순 메모리 부족이 아니라 SSD I/O와 expert cache eviction에 있다는 점을 분명히 보여준 시스템 논문입니다.
이 논문만의 novelty
MoE inference를 “메모리 적재” 문제가 아니라 “routing-aware cache policy” 문제로 바꾸고, recency+frequency 기반 FFN cache policy로 해결하려 했다는 점입니다.
주요 한계
논문 구현 성능이 곧바로 일반 런타임에 재현되진 않을 수 있고, Apple Silicon 환경에서는 별도 backend 최적화 문제가 남습니다.
최종 결론
이 논문은 로컬 MoE 실무에서 “큰 모델을 올릴 수 있느냐”보다 “expert를 얼마나 똑똑하게 SSD에서 덜 읽게 만드느냐”가 더 중요하다는 점을 보여줍니다. 즉 로컬 LLM 실무자에게는 모델 논문보다 운영체제/스토리지/캐시 정책 논문으로 읽는 것이 맞습니다.
[문제 제기]
MoE 모델이 느린 이유는 연산이 아니라 SSD에서 expert를 자꾸 다시 읽어오기 때문인데,
기존 LRU/LFU 캐시는 곧 다시 쓸 expert를 잘못 지워서 비효율이 발생합니다.
[해결 방법론]
본 논문은 "어떤 expert를 지울지"를 결정하는 작은 MLP를 따로 학습시키며,
입력은 recency, frequency / 출력은 "그 expert를 지웠을때 후회(재사용)"을 최소화하는 것입니다.
결과적으로 이를 통해 SSD I/O를 줄여, Inference 속도를 최대 2.6배 개선하는 성과를 거두었다고 합니다.



