
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Battery AI
- tensorflow
- 칼만필터
- Deep learning
- state of health
- 배터리 딥러닝
- 머신러닝
- 텐서플로우
- Azure
- 코드로 이해하는 딥러닝
- Battery modeling
- Battery SOH
- Battery Deep Learning
- 배터리 열화
- Battery Management System
- 배터리 연구
- 배터리 모델링
- Incremental Capacity Analysis
- 머신러닝 코드
- 리튬배터리
- 코이딥
- 딥러닝
- 배터리 진단
- AzureML
- 딥러닝 코드
- 배터리 EIS
- bms
- eis
- 배터리 AI
- Machine Learning
- Today
- Total
Engineering insight
[AAAI-2019] TabNet : Attentive Interpetable Tabular Learning 본문
[AAAI-2019] TabNet : Attentive Interpetable Tabular Learning
Free-Nomad 2024. 1. 18. 14:10논문 전문 : https://arxiv.org/abs/1908.07442
[출처] https://doi.org/10.1609/aaai.v35i8.16826
※ The picture and content of this article are from the original paper.
This article is more of an intuitive understanding than academic analysis.
[논문 요약]
TabNet : Attentive Interpretable Tabular Learning

Tabular Data를 다루는 분들에게는 꽤나 유명한(Citation 800이상) 구글에서 나온 TabNet 논문입니다.
당시에는 Tab Data 기준으로는 SOTA 성능이였습니다만, Tabular는 이미지대비 특히 데이터의 형태/목적에 따라서 성능이 천차만별인 관계로 Transformer처럼 완벽하게 "이 모델로 통일한다" 이런 것은 아직 나오지않은것 같습니다.
Contents
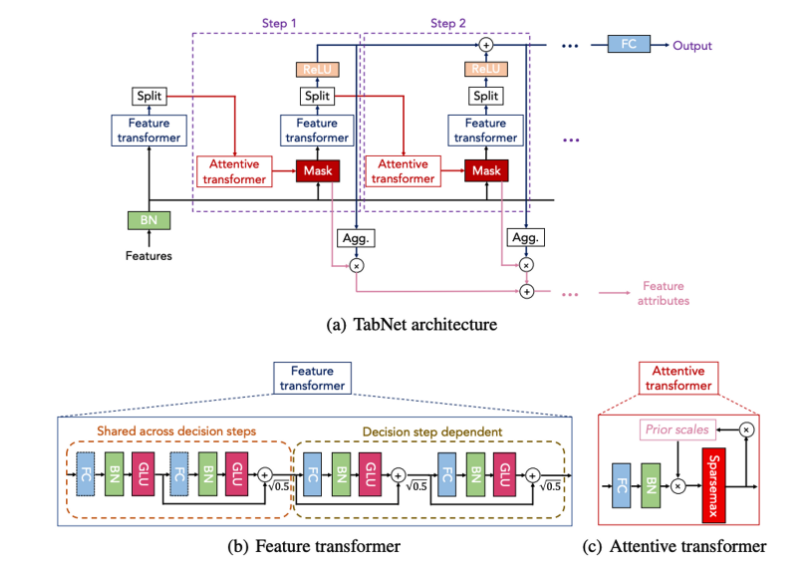
TabNet에 관한 모든것이 담긴 그림입니다.
여기서, Transformer라 되어있는 부분이 있어 해깔리실수있는데 "Attention is all you need"의 Transformer는 아닙니다. 최근에는 Attention is all you need 논문의 모델을 Transformer라고 대명사로 부르지만, 이때당시만해도 그냥 복합적인 모델들의 대명사로도 쓰이곤 했었습니다.
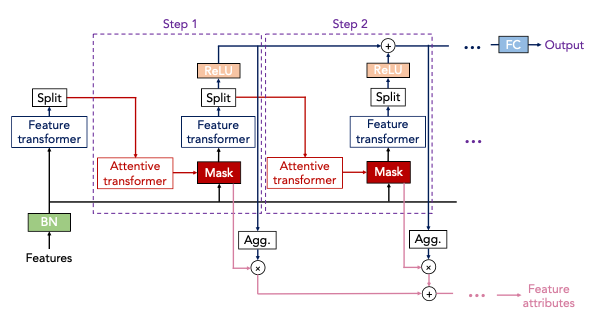
전체 아키텍쳐부터 알아보겠습니다.
데이터를 입력하면 Batch Normalization을 수행하고, Feature Transformer를 지나갑니다.

여기서 Feature Transformer란 FCNN(Fully Connected Neural Network)와 GLU(Gated Linear Unit), Batch Norm으로 구성된 일련의 Stacking Model입니다.
여기서 FC와 BN은 그렇다쳐도 GLU가뭐야? GRU(Gated Recurrent Unit) 오타아니야? 라고 생각하실수도 있지만, 전혀 다른 모델입니다.
GLU는 Gated Linear Unit으로, 입력데이터를 x라고 가정하면 x*(sigmoid(Wx+b))를 수행해주는 Layer라고 보시면됩니다. 단일 Perceptron Layer sigmoid(Wx+b)에 x를 곱해준 형태입니다. 어떻게보면 여기서 sigmoid(Wx+b)부분이 Attention Score처럼 쓰인다고도 볼수있습니다.
즉, 입력데이터에 대해 중요도를 어느정도 반영하는 선형 레이어입니다.
이 Feature Transformer를 거치고는 'Split'이라고 되어있는데, '복제'라고 보시는편이 맞습니다. 즉, Feature Transformer의 출력을 여러 방향으로 복제하여 전송한다는 뜻입니다.

이후, Split된 데이터는 Attentive Transformer로 들어가는데 여기서 Attentive Transformer라는 부분이 중요합니다.
Attentive Transformer는 직접적으로 입력데이터에 대해 중요도(Attention Score)를 계사냏주는 방식입니다. 단, "Attention is all you need"에서는 Scaled dot product attention을 사용했지만, 여기서는 SparseMax라는 테크닉을 사용합니다.
SparseMax라는 테크닉은 기존의 softmax를 통한 확률적 Attention Score를 구하는것이 아닌, 특정 임계치 이하의 값들은 0으로 만듦으로써, Attention Score를 계산함과 더불어 Masking 기능까지 탑재한 스킬입니다.
여기선 SparseMax를 구하는 방법이 핵심이니, 예를들어 한번 계산해보겠습니다.

상기와 같이, Z=[1.5 0.5 2 -1 1]이라는 5차원 벡터가 있다고 가정하고, SparseMax값이 어떻게 나오는지 계산해보겠습니다. 첫번째로는, 내림차순으로 Sorting을 진행합니다.
그리고 이 내림차순 Sorting한 값을 Z로 바꿉니다. Z=[2 1.5 1 0.5 -1]

그다음, 왼쪽부터 오른쪽으로 누적합을 수행합니다.

그다음, J번째 위치에 있는 값을 (1+J)*Z_j 를 하기와 같이 수행합니다.

그러면 상기와 같이 결과가 나오는데요, 이것과 누적합 Matrix를 비교해서 (1+J)*Z_J > 누적합중 가장큰 J를 찾습니다.

즉, J=3일때가 (1+J)*Z_J>누적합중 가장 큰 J입니다.
이를 수식으로 K=max{j | (1+J)*Z_J > Sum(Z_J)} 라고 부릅니다.
그다음, Z_k = (누적합(J) - 1)/(J) = (4.5-1)/(3) = 1.166를 계산해줍니다.

그다음, 가장 맨 처음에 Sorting하기 전 원본 Z에 대해 각 J마다 Z_k를 빼줍니다.

마지막으로, 음수인 부분을 모두 0으로하고 전체합이 1이되도록 정규화를 수행합니다.

그러면 최종으로 이러한 형태가 나오게 되는데, 이것이 SparseMax를 통한 Attention + Mask를 구하는 방식입니다.
이것에 대한 상세한 문헌은 하기 논문에서도 찾으실 수 있습니다.
https://arxiv.org/abs/1602.02068
From Softmax to Sparsemax: A Sparse Model of Attention and Multi-Label Classification
We propose sparsemax, a new activation function similar to the traditional softmax, but able to output sparse probabilities. After deriving its properties, we show how its Jacobian can be efficiently computed, enabling its use in a network trained with bac
arxiv.org
정리하자면, 상기와 같은 방식을 통해 Attentive Transformer는 Mask + Attention을 하는 역할을 합니다.
그리고 Split하고 다시 Attentive Transformer를 거치거나 ReLU를 거치고... 이런식으로 Feature Transformer와 Attentive Transformer를 여러번 거치면서 학습하게 되는것이 TabNet의 핵심입니다.

TabNet을 활용한 다양한 Tabular Data에 대한 성능은 상기와 같습니다. 많은 부분에서 SOTA이거나, SOTa보다 살짝 부족한 모습을 보여줍니다.
Results
2019년 당시에는 SOTA에 가까운 성능을 보여주었던 기술입니다.
본 논문은 Transformer를 아주 간단하게 설계했기때문에 잘 터졌다면 초대형 논문이 되었을수도 있을것 같은데, 왜인지 Tabular쪽은 그렇게 주목받지는 못하는것 같습니다.
SparseMax와 GLU라는것은 Tabnet외에도 다른형태로도 활용할 수 있으니 한번 보시면 좋을것 같습니다.
참조
[1] https://doi.org/10.1609/aaai.v35i8.16826
[2] https://arxiv.org/abs/1602.02068
'AI > AI Paper review' 카테고리의 다른 글
| [NIPS-2014] Generative Adversarial Nets (2) | 2024.01.25 |
|---|---|
| [KDD-2019] Time-Series Anomaly Detection Service at Microsoft (3) | 2024.01.22 |
| [ICML-2021] Tabular Data:Deep Learning is Not All You Need (2) | 2024.01.11 |
| [NIPS-2017] Attention is all you need (0) | 2023.12.23 |
| [CVPR-2018] ESRGAN : Enhanced Super-Resolution Generative Adversarial Networks (2) | 2023.12.11 |



