
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Machine Learning
- Battery AI
- state of health
- 코이딥
- tensorflow
- Battery modeling
- 배터리 진단
- 칼만필터
- bms
- 머신러닝
- 배터리 모델링
- 배터리 EIS
- 딥러닝
- 배터리 열화
- 배터리 연구
- Battery Management System
- Deep learning
- 머신러닝 코드
- eis
- AzureML
- Incremental Capacity Analysis
- 리튬배터리
- Azure
- 배터리 AI
- 배터리 딥러닝
- 딥러닝 코드
- Battery Deep Learning
- Battery SOH
- 텐서플로우
- 코드로 이해하는 딥러닝
- Today
- Total
Engineering insight
[Reinforcement Learning-5] Deep Q-Network으로 최적경로 찾기 본문
[Reinforcement Learning-5] Deep Q-Network으로 최적경로 찾기
Free-Nomad 2021. 9. 5. 11:56[이전글]
https://limitsinx.tistory.com/154
[강화학습-4] Deep Q-Network(DQN)에 대한 간단한 이해
Deep Q Learning(DQN)? 강화학습(Reinforcement Learning)과 심층학습(Deep Learning)을 섞으려는 시도는 예전부터 있었습니다. 하지만, 비교적 최근에 들어서야 DeepMind사가 발표한 "DQN"논문에 의해 현실에 적..
limitsinx.tistory.com
이전글에서 정리했던 Deep-Q Network를 간단한 예제로 확인해보겠습니다!
DQN으로 미로찾기
출처 : Deep Reinforcement Learning in Action, Jpub
DQN을 미로찾기에 접목하기위해 필요한 기본파일은 상기와 같습니다.
(DQN을 적용하는게 메인이기에, 미로찾기 게임을 어떻게 세팅하느냐는 참고도서를 그대로 활용했습니다.)
환경 세팅
저는 Google Colaboratory를 사용했고, cd 명령어를 통해 현재 위치에 위의 GridBoard/world를 저장해주고 임포트해옵니다.

Gridworld(4)는 4X4 미로찾기 환경을 만들어준다는 의미입니다.

[미로찾기 환경확인]
'+' : 목적지
'-' : 절벽(가면안되는곳)
'W' : Wall(지나갈 수 없는곳)
'P' : Player의 현위치 ; 처음 환경세팅하고 나오는 플레이어의 위치가 시작점

4X4의 미로를 만들어줬는데, 게임보드를 그려보면 4X4X4의 tensor가 나오게됩니다.
(+,-,W,P 각각에 대해 보드에서 동작하는것을 그리기때문에 Tensor가 4개 설정)
Player는 위/아래/좌/우 4개로 움직일 수 있으며, Reward는 목표지점(+)에 도착시 +10,
절벽(-)에 도착시 -10, 이외의 상태에서 종료될경우 -1로 주었습니다.(기본세팅)

DQN 신경망 구성

4x4x4 Input을 64개의 벡터로 변환하여 학습하는 신경망을 구성합니다.
64개의 벡터는 현재상태(state)를 나타냅니다.

결국 Neural Network를 Q-Learning에 사용해주는 이유는, 현재상태(state)를 input으로 넣었을때 각 Action별 Q(s,a)를 알아내기 위해서입니다.
DQN모델에 Randomness를 주기위해 E-greedy 탐색법을 적용합니다. (학습 진행마다 입실론 감소예정)
Q-table

1000번의 학습을 통해 Q-table을 만드는 부분입니다.
state1은 현재 state입니다.(t)

현재 state에서의 Q값은 qval이며, epsilon이하의 확률일시 randomness를 주어
argmax(Q)만 보는것이 아닌, 일정부분에서 다른 최적값을 탐색할 수 있는 여지를 남겨둡니다.
action_ 은 보통 argmax(Q(s,a))로 Q값이 가장 높은 action을 선택하는것입니다.
최상의 action으로 game.makeMove를 하게되면 이제 현재상태는 (t+1)이 됩니다.

reward를 통해 Q(s_t)와 Q(s_t+1)의 보상(Reward)를 구해주고,
argmax(Q(s_t+1,a))를 구하기 위해 다시한번 model(Neural Network)를 통과시킵니다.
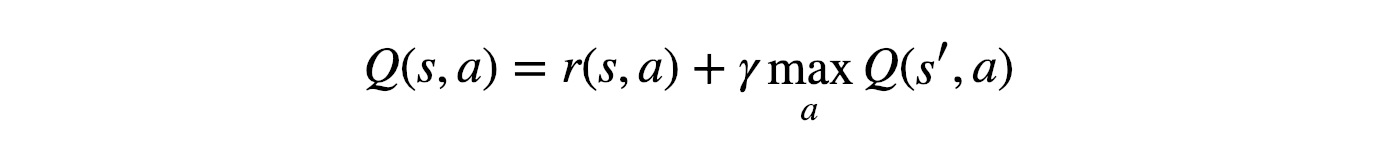

최종적으로 얻어지는 Y = R + (gamma * maxQ)로 벨만방정식이 나오게됩니다.
이전 개념글에서 정리했다시피, Q-Learning은 벨만방정식을 기반으로 동작하며,
이렇게 얻어진 Q(s,a)를 통해 Loss값을 구하고 학습을 진행합니다.
(loss = loss_fn(X,Y)), X : Target, Y : Predict

1000번 학습을 진행하다보면 Loss값이 쭉 떨어지고, Q-table이 완성됩니다.
즉, DQN을 위한 Neural Network 모델이 완성된것입니다.
이제는 state만 알면 Q(s,a)를 알 수 있습니다!
DQN구현

Gridworld를 통해 test_game을 만들어줍니다.
(환경세팅)

Q-table을 Neural Network로 이미 만들어놓았기에, model(state)를 통해 얻어지는 qval을 기준으로, action을 취합니다.
qval = model(state) : NN을 통해 state에서 취할 수있는 모든 Q(s,a)취득
action = np.argmax(qval) : Q(s,a)가 최대가되는 action선택
test_game.makeMove(action) : Q(s_t+1), 즉 다음 state로 넘어갑니다.

① 현재 state에서 model(Neural Network)를 통해 Q(s,a) 도출
② ①을 통해 도출한 최대보상 action을 선택해서 수행
③ 현재 state를 t+1로 변환
위의 1~3 과정을 목표지점에 도착할때까지 반복합니다.
결과

Player가 정확하게 최단거리로 동작하는것을 확인할 수 있습니다.
즉, Neural Network로 만들어낸 Q-table이 아주 잘 동작한다는것이죠!
epoch = 10으로 한번 돌려보면, 학습횟수가 적어 Q-table이 제대로 만들어지지 않음을 확인할 수 있습니다.

Code
#cd /content/drive/MyDrive/Colab Notebooks/Reinforcement Learning/Qnetwork
from Gridworld import Gridworld
game = Gridworld(size=4, mode='static')
game.display()
import numpy as np
import torch
from Gridworld import Gridworld
import random
from matplotlib import pylab as plt
l1= 64 # 4X4X4
l2 = 150
l3 = 100
l4 = 4 #action
model = torch.nn.Sequential(
torch.nn.Linear(l1,l2),
torch.nn.ReLU(),
torch.nn.Linear(l2,l3),
torch.nn.ReLU(),
torch.nn.Linear(l3,l4)
)
loss_fn = torch.nn.MSELoss()
learning_rate = 1e-3
optimizer = torch.optim.Adam(model.parameters(),lr = learning_rate)
gamma = 0.9
epsilon = 1.0
action_set = {
0: 'u',
1: 'd',
2: 'l',
3: 'r',
}
epochs = 10
losses = [] #A
for i in range(epochs): #B
game = Gridworld(size=4, mode='static') #C
state_ = game.board.render_np().reshape(1,64) + np.random.rand(1,64)/10.0 #D
state1 = torch.from_numpy(state_).float() #E
status = 1 #F
while(status == 1): #G
qval = model(state1) #H
qval_ = qval.data.numpy()
if (random.random() < epsilon): #I
action_ = np.random.randint(0,4)
else:
action_ = np.argmax(qval_)
action = action_set[action_] #J
game.makeMove(action) #K
state2_ = game.board.render_np().reshape(1,64) + np.random.rand(1,64)/10.0
state2 = torch.from_numpy(state2_).float() #L
reward = game.reward()
with torch.no_grad():
newQ = model(state2.reshape(1,64))
maxQ = torch.max(newQ) #M
if reward == -1: #N
Y = reward + (gamma * maxQ)
else:
Y = reward
Y = torch.Tensor([Y]).detach()
X = qval.squeeze()[action_] #O
loss = loss_fn(X, Y) #P
print(i, loss.item())
#clear_output(wait=True)
optimizer.zero_grad()
loss.backward()
losses.append(loss.item())
optimizer.step()
state1 = state2
if reward != -1: #Q
status = 0
if epsilon > 0.1: #R
epsilon -= (1/epochs)
def test_model(model, mode='static', display=True):
i = 0
test_game = Gridworld(mode=mode)
state_ = test_game.board.render_np().reshape(1,64) + np.random.rand(1,64)/10.0
state = torch.from_numpy(state_).float()
if display:
print("Initial State:")
print(test_game.display())
status = 1
while(status == 1): #A
qval = model(state)
qval_ = qval.data.numpy()
action_ = np.argmax(qval_) #B
action = action_set[action_]
if display:
print('Move #: %s; Taking action: %s' % (i, action))
test_game.makeMove(action)
state_ = test_game.board.render_np().reshape(1,64) + np.random.rand(1,64)/10.0
state = torch.from_numpy(state_).float()
if display:
print(test_game.display())
reward = test_game.reward()
if reward != -1:
if reward > 0:
status = 2
if display:
print("Game won! Reward: %s" % (reward,))
else:
status = 0
if display:
print("Game LOST. Reward: %s" % (reward,))
i += 1
if (i > 15):
if display:
print("Game lost; too many moves.")
break
win = True if status == 2 else False
return win
test_model(model)
'AI > Reinforcement Learning' 카테고리의 다른 글
| [Reinforcement Learning-6] Deep Q-Network Cartpole 구현 (0) | 2021.09.05 |
|---|---|
| [Reinforcement Learning-4] Deep Q-Network(DQN)에 대한 간단한 이해 (0) | 2021.08.29 |
| [Reinforcement Learning-3] Q-Learning으로 최적경로 찾기 (2) | 2021.08.28 |
| [Reinforcement Learning-2] Q-Learning에 대한 간단한 이해 (0) | 2021.08.26 |
| [Reinforcement Learning-1] Thompson sampling model (2) | 2021.08.26 |



