
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 배터리 EIS
- Battery AI
- 딥러닝
- 텐서플로우
- 배터리 딥러닝
- Deep learning
- Battery Deep Learning
- 배터리 AI
- 머신러닝
- Battery Management System
- 리튬배터리
- 배터리 열화
- 배터리 연구
- state of health
- Incremental Capacity Analysis
- 배터리 모델링
- 딥러닝 코드
- Azure
- 칼만필터
- 배터리 진단
- AzureML
- Machine Learning
- 코드로 이해하는 딥러닝
- eis
- Battery modeling
- 코이딥
- bms
- 머신러닝 코드
- Battery SOH
- tensorflow
- Today
- Total
Engineering insight
[pytorch 따라하기-8] DC-GAN(Deep Convolutional Generative Adversarial Network) 구현 본문
[pytorch 따라하기-8] DC-GAN(Deep Convolutional Generative Adversarial Network) 구현
Free-Nomad 2021. 7. 27. 16:21[pytorch 따라하기-1] 구글 Colab에 pytorch 세팅하기 https://limitsinx.tistory.com/136
[pytorch 따라하기-2] Tensor생성 및 Backward https://limitsinx.tistory.com/137
[pytorch 따라하기-3] 경사하강법을 통한 선형회귀 구현 https://limitsinx.tistory.com/138
[pytorch 따라하기-4] 인공신경망(ANN) 구현 https://limitsinx.tistory.com/139
[pytorch 따라하기-5] 합성곱신경망(CNN) 구현 https://limitsinx.tistory.com/140
[pytorch 따라하기-6] Neural Style Transfer 구현 https://limitsinx.tistory.com/141
[pytorch 따라하기-7] pix2pix 구현 https://limitsinx.tistory.com/142
※이 전글에서 정리한 코드/문법은 재설명하지 않으므로, 참고부탁드립니다
※해당 글은 PC에서 보기에 최적화 되어있습니다.
GAN이란?
Deep Learning계에서 한때 큰 변혁을 불러일으켜왔던 알고리즘 "GAN"을 정리해보겠습니다.
GAN이전의 딥러닝들은, Training Data를 주고 복잡한 알고리즘(CNN,RNN,...)을 통과시켜 어떤 Output을 추정 및 예측하는것이 주류였는데요
GAN이라는것은 전혀 다른 개념으로 딥러닝에 접근합니다.
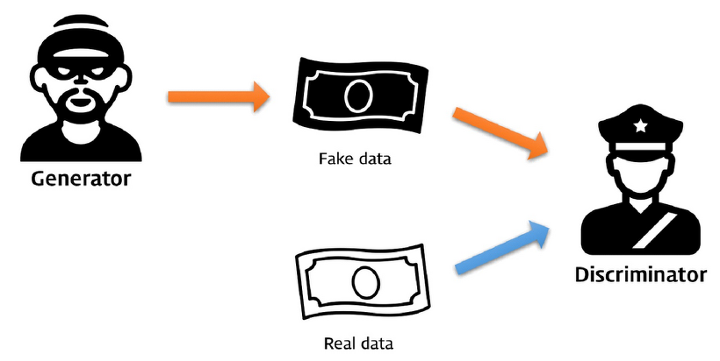
GAN의 컨셉
도둑(Generator)과 경찰(Discriminator)이 있습니다.
경찰에게만 각 국가별 지폐 실제 이미지를 주고, 도둑은 도화지부터 시작해서 매번 그려나갈때마다 경찰에게 확인을 받습니다.
처음에는 도둑이 그려낸 지폐를 바로바로 경찰이 찾아냅니다.
하지만, 시간이 지날수록 도둑이 지폐를 위조하는 능력이 점점 증가하게되고 이에따라 경찰도 점점 해깔리게됩니다.
결국에는 도둑이 만든 위조지폐와 실제 지폐를 경찰이 분간해낼 확률이 50%(Entropy 최대지점)가 되면 도둑은 완벽한 지폐위조범이 되는것입니다.
활용방안
오케이! 위조지폐 만드는거 알겠고 GAN의 컨셉은 알겠다! 그럼 어떻게 쓸수있나요?
경찰에게 주어지는 데이터가 지폐가아니라 반고흐의 그림이라고 생각해봅시다.
GAN학습이 성공적으로 이루어질때쯤이면, 도둑은 완벽에 가깝게 반고흐의 세계가 담긴 그림을 완전 재창조해낼것입니다.
사람의 사진을 넣었다 생각해봅시다.
위조범은 세상에 존재하지도 않고 본적도 없지만, 실제사람과 전혀 구분할 수 없는 이미지들을 무한정 만들어낼것입니다.
자율주행에 적용해볼까요?
자율주행의 실제차량 이미지데이터는 아주 얻기가 어렵고 제한적이죠
GAN으로 실제차량 이미지 데이터를 무한정 찍어낼 수 있다면 어떨까요?
이렇듯, GAN은 활용의 관점에따라 엄청난 양날의 검이될 수 있는 강력한 기술입니다.
이런 GAN의 학습과정에 CNN을 접목시켜, 학습률과 성능을 아주 끌어올린것이 DC-GAN입니다.

저는 이 DC-GAN을, pytorch에서 기본제공해주는 datasets중 STL-10이라고 하는
여러가지 동물/사물들의 컬러데이터를 학습하여, 새로운것들을 만들어보고자 합니다.

코드
import torch
import torch.nn as nn
from torchvision import datasets
import torchvision
from torchvision.transforms.functional import to_pil_image
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import torch.nn.functional as F
import os
import time
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
path2data = './data'
os.makedirs(path2data, exist_ok=True)
h, w = 64, 64
#h, w = 256, 256
mean = (0.5, 0.5, 0.5)
std = (0.5, 0.5, 0.5)
transform = transforms.Compose([
transforms.Resize((h,w)),
transforms.ToTensor(),
transforms.Normalize(mean, std)
])
# STL-10 dataset 불러오기
train_ds = datasets.STL10(path2data, split='train', download=True, transform=transform)
#train_ds = FacadeDataset(path2img, transform = transform)
#test_ds = FacadeDataset(path2img_test, transform = transform)
#train_ds = train_ds[0]
#print(len(train_ds)) # goh image 3
#print(train_ds.__getitem__(1))
img, label = train_ds[0]
plt.imshow(to_pil_image(0.5*img+0.5))
#batch_size = 1
batch_size = 64
train_dl = DataLoader(train_ds, batch_size=batch_size, shuffle=False)
params = {'nz':100, # noise 수
'ngf':64,
'ndf':64,
'img_channel':3,
}
class Generator(nn.Module):
def __init__(self, params):
super().__init__()
nz = params['nz']
ngf = params['ngf']
img_channel = params['img_channel']
self.dconv1 = nn.ConvTranspose2d(nz,ngf*8,4, stride=1, padding=0, bias=False)
self.bn1 = nn.BatchNorm2d(ngf*8)
self.dconv2 = nn.ConvTranspose2d(ngf*8,ngf*4, 4, stride=2, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(ngf*4)
self.dconv3 = nn.ConvTranspose2d(ngf*4,ngf*2,4,stride=2,padding=1,bias=False)
self.bn3 = nn.BatchNorm2d(ngf*2)
self.dconv4 = nn.ConvTranspose2d(ngf*2,ngf,4,stride=2,padding=1,bias=False)
self.bn4 = nn.BatchNorm2d(ngf)
self.dconv5 = nn.ConvTranspose2d(ngf,img_channel,4,stride=2,padding=1,bias=False)
def forward(self,x):
x = F.relu(self.bn1(self.dconv1(x)))
x = F.relu(self.bn2(self.dconv2(x)))
x = F.relu(self.bn3(self.dconv3(x)))
x = F.relu(self.bn4(self.dconv4(x)))
x = torch.tanh(self.dconv5(x))
return x
x = torch.randn(1,100,1,1, device=device)
model_gen = Generator(params).to(device)
out_gen = model_gen(x)
print(out_gen.shape)
class Discriminator(nn.Module):
def __init__(self,params):
super().__init__()
img_channel = params['img_channel'] # 3
ndf = params['ndf'] # 64
self.conv1 = nn.Conv2d(img_channel,ndf,4,stride=2,padding=1,bias=False)
self.conv2 = nn.Conv2d(ndf,ndf*2,4,stride=2,padding=1,bias=False)
self.bn2 = nn.BatchNorm2d(ndf*2)
self.conv3 = nn.Conv2d(ndf*2,ndf*4,4,stride=2,padding=1,bias=False)
self.bn3 = nn.BatchNorm2d(ndf*4)
self.conv4 = nn.Conv2d(ndf*4,ndf*8,4,stride=2,padding=1,bias=False)
self.bn4 = nn.BatchNorm2d(ndf*8)
self.conv5 = nn.Conv2d(ndf*8,1,4,stride=1,padding=0,bias=False)
def forward(self,x):
x = F.leaky_relu(self.conv1(x),0.2)
x = F.leaky_relu(self.bn2(self.conv2(x)),0.2)
x = F.leaky_relu(self.bn3(self.conv3(x)),0.2)
x = F.leaky_relu(self.bn4(self.conv4(x)),0.2)
x = torch.sigmoid(self.conv5(x))
return x.view(-1,1)
x = torch.randn(16,3,64,64,device=device)
#x = torch.randn(16,3,128,128,device=device)
model_dis = Discriminator(params).to(device)
out_dis = model_dis(x)
print(out_dis.shape)
def initialize_weights(model):
classname = model.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(model.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(model.weight.data, 1.0, 0.02)
nn.init.constant_(model.bias.data, 0)
model_gen.apply(initialize_weights);
model_dis.apply(initialize_weights);
loss_func = nn.BCELoss()
from torch import optim
lr = 2e-4
#lr = 0.0005
beta1 = 0.5
beta2 = 0.999
opt_dis = optim.Adam(model_dis.parameters(),lr=lr,betas=(beta1,beta2))
opt_gen = optim.Adam(model_gen.parameters(),lr=lr,betas=(beta1,beta2))
model_gen.train()
model_dis.train()
batch_count=0
num_epochs=10
start_time = time.time()
nz = params['nz'] # 노이즈 수 100
loss_hist = {'dis':[],
'gen':[]}
for epoch in range(num_epochs):
for xb, yb in train_dl:
ba_si = xb.shape[0]
#ba_si = 13*13
#print('basi : ', ba_si)
xb = xb.to(device)
yb_real = torch.Tensor(ba_si,1).fill_(1.0).to(device)
yb_fake = torch.Tensor(ba_si,1).fill_(0.0).to(device)
# generator
model_gen.zero_grad()
z = torch.randn(ba_si,nz,1,1).to(device)
out_gen = model_gen(z)
out_dis = model_dis(out_gen)
g_loss = loss_func(out_dis,yb_real)
g_loss.backward()
opt_gen.step()
# discriminator
model_dis.zero_grad()
out_dis = model_dis(xb)
loss_real = loss_func(out_dis,yb_real)
out_dis = model_dis(out_gen.detach())
loss_fake = loss_func(out_dis,yb_fake)
d_loss = (loss_real + loss_fake) / 2
d_loss.backward()
opt_dis.step()
loss_hist['gen'].append(g_loss.item())
loss_hist['dis'].append(d_loss.item())
batch_count += 1
if batch_count % 100 == 0:
print('Epoch: %.0f, G_Loss: %.6f, D_Loss: %.6f, time: %.2f min' %(epoch, g_loss.item(), d_loss.item(), (time.time()-start_time)/60))
# loss history
plt.figure(figsize=(10,5))
plt.title('Loss Progress')
plt.plot(loss_hist['gen'], label='Gen. Loss')
plt.plot(loss_hist['dis'], label='Dis. Loss')
plt.xlabel('batch count')
plt.ylabel('Loss')
plt.legend()
plt.show()
path2models = './models/'
os.makedirs(path2models, exist_ok=True)
path2weights_gen = os.path.join(path2models, 'weights_gen.pt')
path2weights_dis = os.path.join(path2models, 'weights_dis.pt')
torch.save(model_gen.state_dict(), path2weights_gen)
torch.save(model_dis.state_dict(), path2weights_dis)
weights = torch.load(path2weights_gen)
model_gen.load_state_dict(weights)
model_gen.eval()
with torch.no_grad():
fixed_noise = torch.randn(16, 100,1,1, device=device)
label = torch.randint(0,10,(16,), device=device)
img_fake = model_gen(fixed_noise).detach().cpu()
print(img_fake.shape)
plt.figure(figsize=(16,16))
for ii in range(16):
plt.subplot(4,4,ii+1)
plt.imshow(to_pil_image(0.5*img_fake[ii]+0.5), cmap='gray')
plt.axis('off')
결과값
epoch = 10,100,300 세번으로 나누어 실행해보았습니다.
위의 컨셉에서 언급했듯, Generator Loss(위조범)와 Discriminator Loss(경찰)이 50%면 성공적으로 학습이 잘 이루어졌다고 할수있는데요,
아래 결과값에서 확인할 수 있다시피 Loss도 중요하지만, 기본적으로 epoch이 많이 반복되는것이 훨씬 중요합니다.
(GAN system이 Collapse되는 문제도 있어, Loss가 발산해버리는 경우도 있습니다.)



STL-10의 이미지셋이 워낙 종류들이 다양한 관계로, 학습된 결과들을 봤을때 뭔가를 표현하려는것 같긴하지만 확실히 분간이 잘안되는것을 볼 수 있는데요
"사람 얼굴들의 집합"처럼 기본적으로 유사한 형태의 이미지들을 GAN으로 학습시키면 훨씬 유의미한 이미지들을 만들어 낼 수 있습니다.
DC-GAN으로 제 사진 한장을 학습시키며 과정을 저장해보니 이렇게나오네요..ㅎㅎ






'DeepLearning Framework & Coding > Pytorch' 카테고리의 다른 글
| [Pytorch-10] One Class SVM(Support Vector Machine, OCSVM), SVDD (2) | 2021.08.11 |
|---|---|
| [pytoroch 따라하기-9] LSTM을 통한 시계열 데이터 예측모델 구현 (1) | 2021.08.03 |
| [pytorch 따라하기-7] pix2pix 구현 (0) | 2021.07.27 |
| [pytorch 따라하기-6] Neural Style Transfer 구현(이미지 합성) (2) | 2021.07.26 |
| [pytorch 따라하기-5] 합성곱신경망(CNN) 구현 (0) | 2021.07.25 |



