
- 분류 전체보기 (328)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- eis
- Battery SOH
- 배터리 EIS
- tensorflow
- Machine Learning
- 배터리 딥러닝
- Battery Deep Learning
- Deep learning
- Kalman filter
- bms
- Battery modeling
- 리튬배터리
- 배터리 진단
- Azure
- 딥러닝 코드
- 코이딥
- 배터리 AI
- 딥러닝
- 배터리 열화
- 코드로 이해하는 딥러닝
- 배터리 모델링
- 머신러닝
- 텐서플로우
- Incremental Capacity Analysis
- Battery Management System
- 머신러닝 코드
- AzureML
- 칼만필터
- state of health
- Battery AI
- Today
- Total
Engineering insight
[코드로 이해하는 딥러닝 2-8] - Data Pre-processing 본문
[코드로 이해하는 딥러닝 2-8] - Data Pre-processing
Free-Nomad 2021. 1. 12. 06:21"Data Pre-Processing"
데이터 전처리(Data pre-processing)은, 머신러닝 및 빅데이터 분석가에게 아주 필요한 기술입니다.
데이터들의 범위는 중구난방이기 때문에 균일화를 해줄 필요가 있기 때문이죠
예를들면, 저는 [1,2,3] [1000,3,4], [10000,5,2] 라는 x_data를 학습시킨다고 가정해보죠
Feature 1은 1~10000의 범위를 갖는동안 나머지는 +-2정도의 값변화를 가지죠
즉, Feature들 간에 값의 scailing차이가 너무 나게되면, 한쪽으로 강한 Bias가 생긴 값들이 나올 수 있다는 것입니다.
따라서, 데이터를 학습시키기전에 전처리를 해주는 과정이 필요한데요
보통, Gaussian pdf를 따른다는 전제하에, Z-score (x-mean(x)/stddev(x))으로 표준 정규화를 해주는 방법을 주로 사용하지만, 가장 간단하게 사용할 수 있는 min max scailing에 관해 설명드리고자 합니다.
min max scailing = (x-min(x))/(x-max(x))를 해주는것으로 전체 값을 0과 1사이로 맞추어주는데 의의가 있습니다.
코드로 보면 직관적입니다. (혹시나 분모가 0이 될것을 방지하고자 아주 작은 숫자를 더해줍니다.)

def min_max_scaler(data):
numerator = data - np.min(data, 0)
denominator = np.max(data, 0) - np.min(data, 0)
# noise term prevents the zero division
return numerator / (denominator + 1e-7)
이렇게 코드를 전처리해주면, 아래의 표처럼 값이 바뀝니다.
[기존]
[828.659973, 833.450012, 908100, 828.349976, 831.659973],
[823.02002, 828.070007, 1828100, 821.655029, 828.070007],
[819.929993, 824.400024, 1438100, 818.97998, 824.159973],
[816, 820.958984, 1008100, 815.48999, 819.23999],
[819.359985, 823, 1188100, 818.469971, 818.97998],
[819, 823, 1198100, 816, 820.450012],
[811.700012, 815.25, 1098100, 809.780029, 813.669983],
[809.51001, 816.659973, 1398100, 804.539978, 809.559998],
[변경]
[[0.99999999 0.99999999 0. 1. 1. ]
[0.70548491 0.70439552 1. 0.71881782 0.83755791]
[0.54412549 0.50274824 0.57608696 0.606468 0.6606331 ]
[0.33890353 0.31368023 0.10869565 0.45989134 0.43800918]
[0.51436 0.42582389 0.30434783 0.58504805 0.42624401]
[0.49556179 0.42582389 0.31521739 0.48131134 0.49276137]
[0.11436064 0. 0.20652174 0.22007776 0.18597238]
[0. 0.07747099 0.5326087 0. 0. ]]
즉, 원래 숫자배열들의 분포(pdf)는 그대로 가져가면서, scailing만 진행해준것입니다!
이렇게 된다면 여러 Feature간에 비교적 밸런스가 맞는 학습을 진행할 수 있습니다.
[코드 전문]
import tensorflow as tf
import numpy as np
def min_max_scaler(data):
numerator = data - np.min(data, 0)
denominator = np.max(data, 0) - np.min(data, 0)
# noise term prevents the zero division
return numerator / (denominator + 1e-7)
xy = np.array(
[
[828.659973, 833.450012, 908100, 828.349976, 831.659973],
[823.02002, 828.070007, 1828100, 821.655029, 828.070007],
[819.929993, 824.400024, 1438100, 818.97998, 824.159973],
[816, 820.958984, 1008100, 815.48999, 819.23999],
[819.359985, 823, 1188100, 818.469971, 818.97998],
[819, 823, 1198100, 816, 820.450012],
[811.700012, 815.25, 1098100, 809.780029, 813.669983],
[809.51001, 816.659973, 1398100, 804.539978, 809.559998],
]
)
# very important. It does not work without it.
xy = min_max_scaler(xy)
print(xy)
'''
[[0.99999999 0.99999999 0. 1. 1. ]
[0.70548491 0.70439552 1. 0.71881782 0.83755791]
[0.54412549 0.50274824 0.57608696 0.606468 0.6606331 ]
[0.33890353 0.31368023 0.10869565 0.45989134 0.43800918]
[0.51436 0.42582389 0.30434783 0.58504805 0.42624401]
[0.49556179 0.42582389 0.31521739 0.48131134 0.49276137]
[0.11436064 0. 0.20652174 0.22007776 0.18597238]
[0. 0.07747099 0.5326087 0. 0. ]]
'''
x_data = xy[:, 0:-1]
y_data = xy[:, [-1]]
tf.model = tf.keras.Sequential()
tf.model.add(tf.keras.layers.Dense(units=1, input_dim=4))
tf.model.add(tf.keras.layers.Activation('linear'))
tf.model.compile(loss='mse', optimizer=tf.keras.optimizers.SGD(lr=1e-5))
tf.model.summary()
history = tf.model.fit(x_data, y_data, epochs=1000)
predictions = tf.model.predict(x_data)
score = tf.model.evaluate(x_data, y_data)
print('Prediction: \n', predictions)
print('Cost: ', score)
[코드 분석]
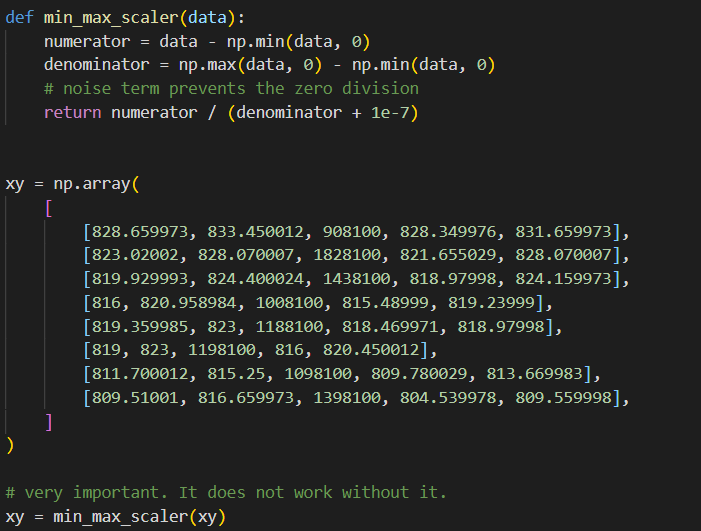
코드는 간단합니다.
기존의, 머신러닝 학습모델 코드에서 min_max_scaler라는 이름으로 위와 같이 함수를 define해주고, 학습할 데이터를 선언한 이후, 한번 함수를 통과시켜주면 됩니다.
참고로 위의 데이터는 어떤 Feature는 100만단위이며, 나머지는 1000을 안넘습니다. 따라서, Weighting과 Bias들이 강하게 집중되는 문제점이 발생할 수 있습니다.
[결과값(min max scaler가 있는경우)]

[결과값(min max scaler가 없는경우)]

min max scaler가 있는경우는 cost 0.3정도로 정확도가 높게 나오는 모습을 확인할 수 있는데요
min max scaler없이 그냥 학습하는 경우는 Cost가 발산해버려서(NAN)학습이 정상적으로 진행되지 않는것을 확인할 수 있습니다.
따라서, 여러가지 특징들에 대해 균일한 portion을 주고 학습을 해보고 싶다고 하시면 scailing을 한번 거치는 코드를 짜주시면 됩니다.
'DeepLearning Framework & Coding > Tensorflow 2.X' 카테고리의 다른 글
| [코드로 이해하는 딥러닝 2-10] - Drop out (0) | 2021.01.14 |
|---|---|
| [코드로 이해하는 딥러닝 2-9] - MNIST를 DNN으로 학습시키기/ReLU (0) | 2021.01.13 |
| [코드로 이해하는 딥러닝 2-7] - Deep and Wide Neural Network(DWNN) (0) | 2021.01.11 |
| [코드로 이해하는 딥러닝 2-6] - Deep Neural Network/XOR (0) | 2021.01.10 |
| [코드로 이해하는 딥러닝 2-5] - Softmax Regression(multiple classification) (0) | 2021.01.09 |



