[코드로 이해하는 딥러닝 0] - 글연재에 앞서 https://limitsinx.tistory.com/27
[코드로 이해하는 딥러닝 1] - Tensorflow 시작 https://limitsinx.tistory.com/28
[코드로 이해하는 딥러닝 2] - Tensorflow 변수선언 https://limitsinx.tistory.com/29
[코드로 이해하는 딥러닝 3] - Tensorflow placeholder변수 https://limitsinx.tistory.com/30
[코드로 이해하는 딥러닝 4] - 선형회귀(Linear Regression) https://limitsinx.tistory.com/31
[코드로 이해하는 딥러닝 5] - 다중선형회귀(Multiple Linear Regression) https://limitsinx.tistory.com/32
[코드로 이해하는 딥러닝 6] - 회귀(Regression)에 대한 다른 접근 https://limitsinx.tistory.com/33
[코드로 이해하는 딥러닝 7] - .txt(.csv)파일 불러오기 https://limitsinx.tistory.com/34
[코드로 이해하는 딥러닝 8] - Logistic Regression(sigmoid) https://limitsinx.tistory.com/35
[코드로 이해하는 딥러닝 9] - Softmax Regression(multiple classification) https://limitsinx.tistory.com/36
※이 전글에서 정리한 코드/문법은 재설명하지 않으므로, 참고부탁드립니다

이번에는 본격적으로 어떤 "데이터 셋"을 학습해보겠습니다.
C의 "Hello World"처럼 대표적인 머신러닝의 학습 데이터셋은 "MNIST"입니다.
여러가지 글씨체로 적힌 0~9 데이터의 모음이죠
이 데이터셋을 학습시켜서, 내가 손으로 쓴 글자를 컴퓨터가 제대로 인식하는지 해보겠습니다.
학습모델은 Softmax activation function으로 진행했습니다.
[코드 전문]
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
import matplotlib.pyplot as plt
import random
tf.set_random_seed(777) # for reproducibility
from tensorflow.examples.tutorials.mnist import input_data
# Check out https://www.tensorflow.org/get_started/mnist/beginners for
# more information about the mnist dataset
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
nb_classes = 10
# MNIST data image of shape 28 * 28 = 784
X = tf.placeholder(tf.float32, [None, 784])
# 0 - 9 digits recognition = 10 classes
Y = tf.placeholder(tf.float32, [None, nb_classes])
W = tf.Variable(tf.random_normal([784, nb_classes]))
b = tf.Variable(tf.random_normal([nb_classes]))
# Hypothesis (using softmax)
hypothesis = tf.nn.softmax(tf.matmul(X, W) + b)
cost = tf.reduce_mean(-tf.reduce_sum(Y * tf.log(hypothesis), axis=1))
train = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(cost)
# Test model
is_correct = tf.equal(tf.argmax(hypothesis, 1), tf.argmax(Y, 1))
# Calculate accuracy
accuracy = tf.reduce_mean(tf.cast(is_correct, tf.float32))
# parameters
num_epochs = 15
batch_size = 100
num_iterations = int(mnist.train.num_examples / batch_size)
with tf.Session() as sess:
# Initialize TensorFlow variables
sess.run(tf.global_variables_initializer())
# Training cycle
for epoch in range(num_epochs):
avg_cost = 0
for i in range(num_iterations):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
_, cost_val = sess.run([train, cost], feed_dict={X: batch_xs, Y: batch_ys})
avg_cost += cost_val / num_iterations
print("Epoch: {:04d}, Cost: {:.9f}".format(epoch + 1, avg_cost))
print("Learning finished")
# Test the model using test sets
print(
"Accuracy: ",
accuracy.eval(
session=sess, feed_dict={X: mnist.test.images, Y: mnist.test.labels}
),
)
# Get one and predict
r = random.randint(0, mnist.test.num_examples - 1)
print("Label: ", sess.run(tf.argmax(mnist.test.labels[r : r + 1], 1)))
print(
"Prediction: ",
sess.run(tf.argmax(hypothesis, 1), feed_dict={X: mnist.test.images[r : r + 1]}),
)
plt.imshow(
mnist.test.images[r : r + 1].reshape(28, 28),
cmap="Greys",
interpolation="nearest",
)
plt.show()
[코드 분석-1]
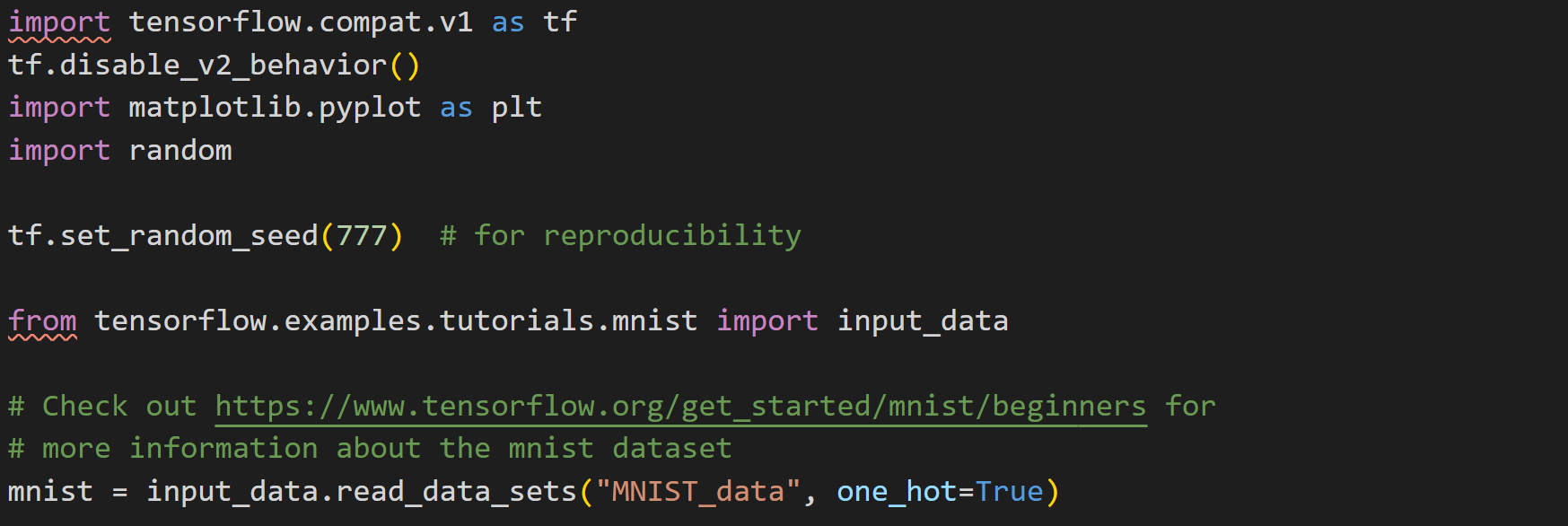
① tf.set_random_seed(777)
: 내컴퓨터에서 random한값을 얻은 결과가, 다른사람이 돌렸을때도 동일하게 나오는것을 의미합니다.
즉, random()의 결과로 제가 1,2,3이 나왔다면 여러분도 1,2,3이 나오게될것입니다. 그냥 짜잘한 스킬입니다.
②★ from tensorflow.examples.tutorials.mnist import input_data
: Tensorflow를 설치하면 기본 examples->tutorials 폴더에 mnist dataset이 같이 깔리게 됩니다.
해당 위치의 mnist데이터를 "input_data"라는 이름으로 불러오는 코드입니다.
③ mnist = input_data.read_data_sets("MNIST_data",one_hot=True)
: 읽어온 input_data를 one hot encoding을 하여 mnist라는 변수이름으로 저장하는것입니다.
※One hot encoding
: 예를들어, 1~4의 숫자를 각각 classification해야된다고 가정해보면,
1인경우에는 [1,0,0,0] 2는 [0,1,0,0], 3은 [0,0,1,0] 4는 [0,0,0,1] 이렇게 표현할 수 있겠죠
즉, N가지 경우의수를 N개의 비트를 통해 표현하는것을 one hot encoding이라고 합니다.
이와 반대로 [0,1,0,0]을 2라고 해독하는것을 one hot decoding이라고 합니다.
[코드 분석-2]
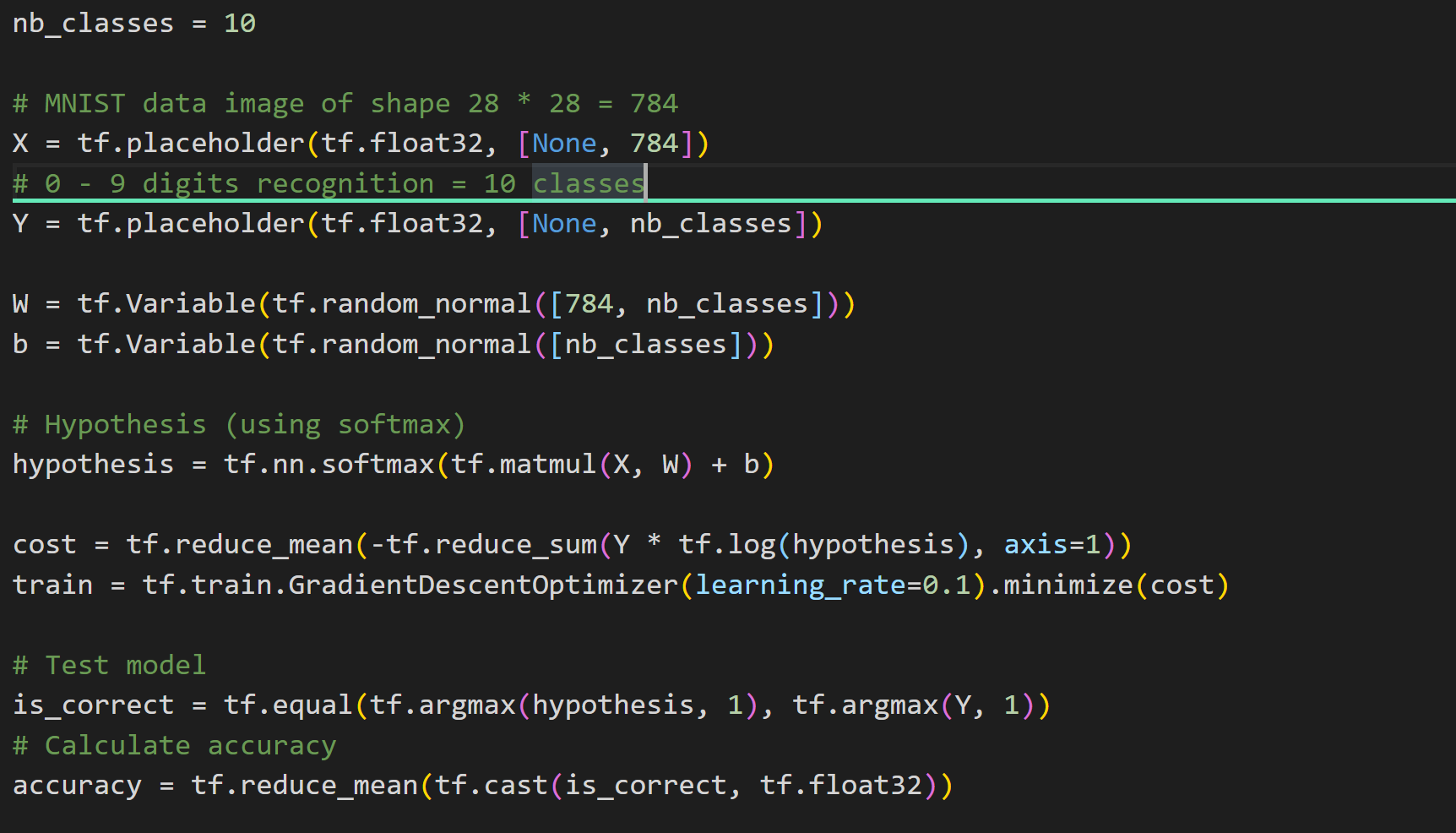
① nb_classes = 10
: number of classes로 classification할 갯수를 나타내는것입니다.
0~9까지 숫자 각각을 분류해야하기에 총 10개의 class입니다.
② X=tf.placeholder(tf.float32, [None,784])
: 각각의 숫자 이미지들은 가로, 세로 28pixels로 총 사진 1장당 784개의 pixel을 가지고 있습니다.
따라서, 각 픽셀마다 Feature(특징)으로 보고 784개의 특징이 있는 데이터로 X를 저장하는 코드입니다.
③ is_correct = tf.equal(tf.argmax(hypothesis,1), tf.argmax(Y,1))
: 학습시킨 결과 정확도를 보기 위한 부분입니다.
argmax(a,1)이란 예를들어, a=[1,2,3,4]라고하면 4가 가장크죠? 이부분만 1로만들고 나머지는 0으로 두는것입니다.
tf.argmax(Y,1)은 실제목표값(Y)를 [0,0,0,...,1,..] 이런식으로 최대값기준 one-hot encoding을 한것입니다.
이 두개를 tf.equal()을 통해 비교하는것인데요,
argmax(hypothesis,1) (추측값)이 예를들어, [0,0,0,1], argmax(Y,1)이 [0,0,0,1]이면 tf.equal()은 True를 return하겠죠?
즉, tf.equal의 output은 [True,false,True,True,false....] 이런식으로 나오게됩니다.
④ accuracy = tf.reduce_mean()
: tf.equal()을 통해 얻어진 array를 평균내는것입니다.
True가 9개 false가 1개였다고 하면, accuracy = 0.9가 됩니다.
[코드 분석-3]

여기서부터 학습모델을 세팅하는 과정입니다.
① num_epochs = 15
: input layer -> output layer -> input layer로 Error Back Propagation까지 총 15회 학습하겠다는 뜻입니다.
② batch_size = 100
: 이미지 데이터는, mnist만 봐도 한 이미지당 특징이 784개로 너무 데이터수가 많기때문에
100개 단위로 끊어서 학습을 진행하겠다는 의미입니다.
따라서, 자연스럽게 num_iterations(학습 반복횟수) = 전체 데이터수/batch size 가 되겠죠
[코드 분석-4]

① for epoch in range(num_epochs)
: num_epochs(15)만큼 학습을 반복한다는 의미
② batch_xs, batch_ys = mnist.train.next_batch(batchsize)
: batch_xs, batch_ys는 100개의 이미지를 784개의 특징으로 분류했을때의 값들이죠
즉, batch_xs는 100행 784열, batch_ys는 100행 10열(one hot encoding)인 상태입니다.
③ avg_cost += cost_val/num_iterations
: 100개씩 쪼개서 학습을하니, 코스트도 100개의 평균씩 점점더해주며 average를 구하는 코드입니다.
[코드 분석-5]

학습은 위에서 다 시키고, 이번에는 Test set을 통해 검증을 해보는 단계입니다.
① accuracy.eval(session = sess, feed_dict = {X: mnist.test.images, Y:mnist.test.labels})
: mnist안에 test용 셋이 따로 있으므로, 해당 image와 label을 X와 Y데이터로 두고 정확도를 구해보는 코드입니다.
② r= random.randint(0,mnist.test.num_examples -1) ~
mnist.test set중에 랜덤하게 1개를 뽑아서, 결과값이 잘 나오는지 테스트해보는 코드입니다.
③ sess.run(tf.argmax(mnist.test.labels[r:r+1],1)))
: mnist.test셋중 one hot encoding(argmax)를 통해 어떤 숫자인지 알아내는 코드입니다. (실제값)
④ sess.run(argmax(hypothesis,1),feed_dict = {X:mnist.test.images[r:r+1]}))
: mnist.test셋중 추측한 값(hypothesis)를 통해 어떤 숫자인지 예측해보는 코드입니다. (예측값)
-> ③과 ④가 동일하게 나온다는것은 학습이 잘 완료되었다는 뜻이겠죠!
[코드 분석-6]

random하게 나온 이미지가 어떤것인지 보여주는것입니다.
여기서 이미지로 0이나왔는데, 결과값이 0이나온다면 학습이 잘되었다는 뜻입니다.
mnist.test.images[r:r+1]은 1행 784열의 형태로 특징이 적혀있기때문에 (28,28)의 사진 픽셀 사이즈에 맞게 reshape해주는 코드입니다.
[결과값]

저는 콘솔창에 결과값이 이렇게 뜨는데요
15번의 epoch를 통해 cost는 0.45까지 줄어들었으며
test set을 통해 측정해본 정확도는 89.51%이고
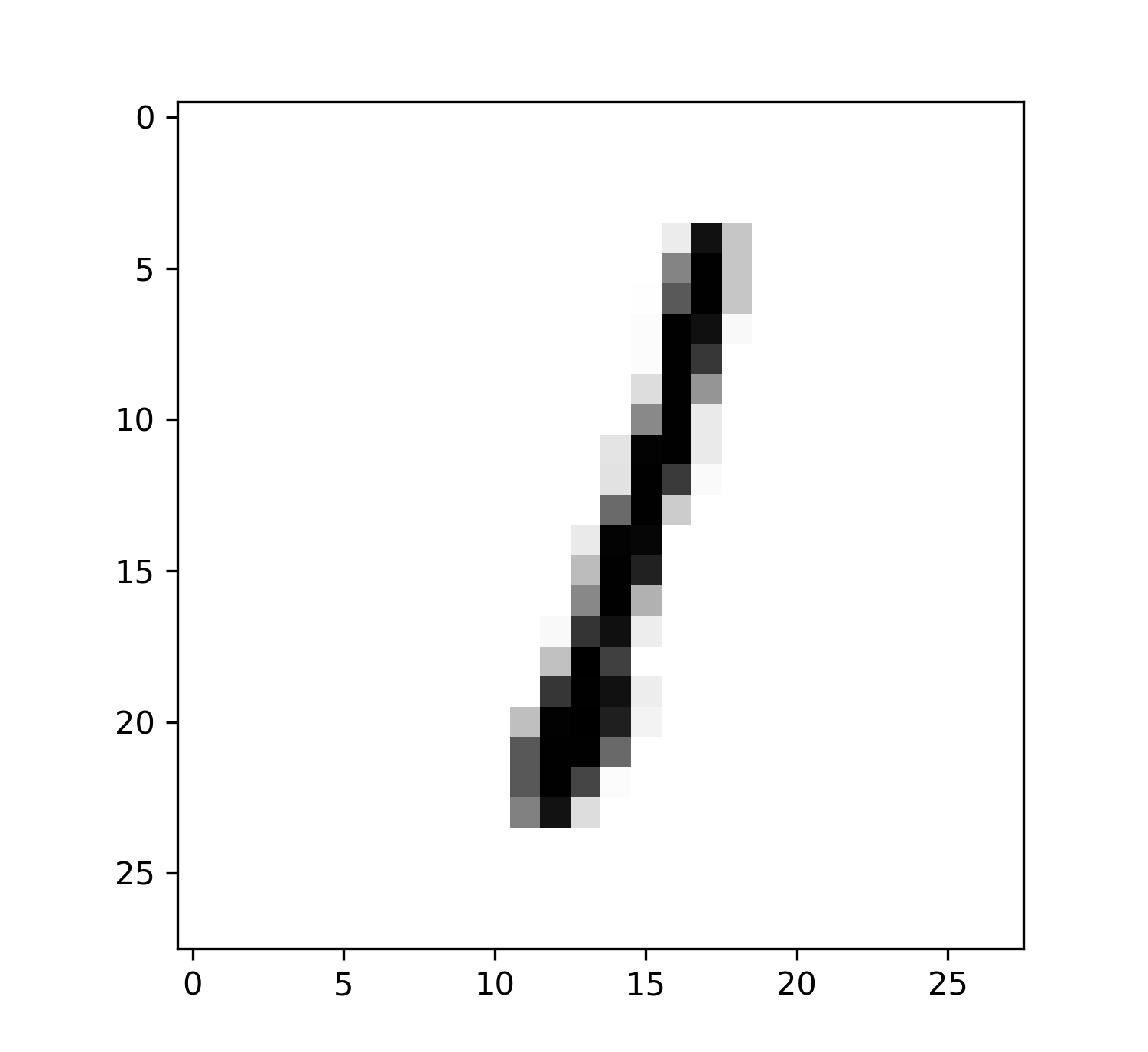
랜덤하게 뽑은수는 1인데 예측값도 1로 잘 맞게나오네요 :)
Summary
0~9까지의 숫자들을 학습시켜보고, 임의의 이미지에서 정확하게 숫자를 판독해내는지 코드로 짜보았습니다.
epoch수를 늘리거나 batch수를 조절해보면서 정확도가 상승할 수 있는 방향에 대해
한번씩 돌려보시면 좋을것 같습니다 :)
'DeepLearning Framework & Coding > Tensorflow 1.X' 카테고리의 다른 글
| [코드로 이해하는 딥러닝 11-EX] - MNIST를 DNN으로 학습해보기/Adam optimizer (0) | 2020.12.25 |
|---|---|
| [코드로 이해하는 딥러닝 11] - Deep Neural Network/XOR (0) | 2020.12.24 |
| [코드로 이해하는 딥러닝 9] - Softmax Regression(multiple classification) (0) | 2020.12.22 |
| [코드로 이해하는 딥러닝 8] - Logistic Regression(sigmoid) (0) | 2020.12.21 |
| [코드로 이해하는 딥러닝 7] - .txt(.csv)파일 불러오기 (0) | 2020.12.20 |




댓글