
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 머신러닝
- Battery SOH
- eis
- 코이딥
- Battery AI
- bms
- Battery Deep Learning
- 텐서플로우
- 배터리 딥러닝
- 딥러닝 코드
- 머신러닝 코드
- 딥러닝
- 배터리 열화
- Battery modeling
- state of health
- Incremental Capacity Analysis
- Azure
- 배터리 진단
- Deep learning
- tensorflow
- 리튬배터리
- 배터리 모델링
- Machine Learning
- 배터리 AI
- AzureML
- Battery Management System
- 배터리 연구
- 배터리 EIS
- 칼만필터
- 코드로 이해하는 딥러닝
- Today
- Total
Engineering insight
XAI(Explaniable AI)에 대한 간단한 이해 본문
설명가능한 인공지능? XAI? 오해와 편견
혹자는 XAI를 한다고 광고하며, 산학과제 및 정부과제를 따가는 모습을 많이 보았습니다.
실제로는 XAI는 아무 상관없는 분야인데 말이죠
"설명가능한 인공지능"이 최근 Hot한 토픽이자 인공지능 한다고 하면 과제비를 서로 주려고 난리인 한국 학계의 냄비 특성때문이 강하기때문입니다.
설명가능한 인공지능은 제가 보기엔 정말 아무것도 아닙니다.
물론, Academic하게 다양한 기법들이 존재하지만, 적어도 실제 딥러닝을 설계하시는분들 중에서도 아주 일부 도메인에서만 사용가능합니다.
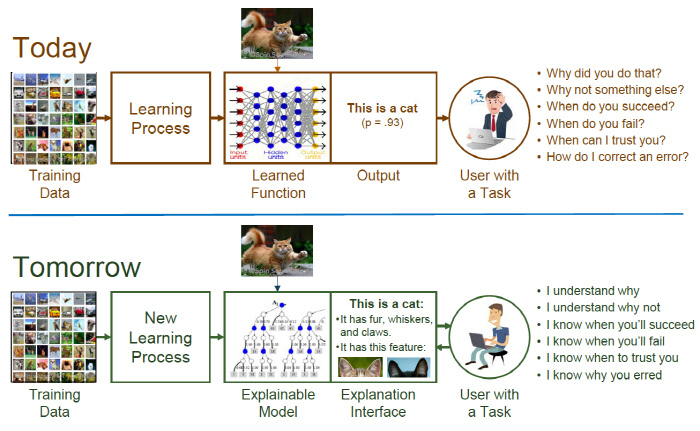
딥러닝을 직접설계해보지 않은사람들, 비전공자들은 누구나 혹할수 있는 말입니다.
딥러닝의 가장 큰 문제가 "Black Box"라는것 아니야?? 이걸 Black Box가 아니고 직접 설명가능하도록 하는것은 꼭 필요하고 좋은일아닌가??
맞습니다.
하지만, 이건 "Black Box"가 뭔지 모르기때문에 이런 생각을 할수있습니다.
Black Box란 뭘까요? 딥러닝은 블랙박스 블랙박스 하는데 블랙박스가 뭐길래 XAI가 필요하다고할까요?
Black Box의 정의는 "물리적 수식에 근거하지 않은, 수학적 해석을 통한 물리적 현상 분석" 입니다.
즉, 딥러닝은 Data Driven Method로 배터리로 치면 물리적 배터리 등가회로 혹은 전기화학적 모델링 없이 데이터만으로 Input과 output간의 관계를 만들어버리는것을 의미하죠
그럼 다시한번 정리해보겠습니다.
딥러닝을 하고, Weight와 Bias가 어떤과정에 의해서 도출되는지 안다고하면, 이게 물리적으로 근거한 수식이되나요??
다시
딥러닝을 하고, XAI에의해 모델의 파라미터들이 일부 설명가능하게 된다고하면, 이게 Black Box가 아닌가요??
아닙니다. 애초에 딥러닝을 사용한다는것 자체가 물리적 모델을 전혀 사용하지 않겠다는 뜻입니다.
(설령 물리적으로 의미가 있는 인자들의 Coefficient값을 목표로 학습하더라도 마찬가지입니다.)
즉, XAI와 Black Box는 전혀관계가 없고, XAI를 하더라도 딥러닝은 여전히 Black Box입니다.
이런 엄밀한 구분을 하지않기때문에 마치 XAI를 쓰면, 모든 딥러닝의 난제들이 풀리는것 마냥 사람들이 알고있습니다.
XAI가 Boom이 이는듯했지만, 금세 가라앉고 잠잠해지고 최근에는 연구가 아주 뎌디게 진행되고있습니다.
상기와 같은 이유들때문입니다.
결국, XAI는 딥러닝 모델을 좀 뜯어보고 일부분이 coefficient가 왜그렇게 나오나, Weight와 Bias가 왜 여기서 좀 높게나오나, Hidden layer가 지나갈수록 어떻게 바뀌나 이런정도를 알수있음에 그치지 않는다는 것입니다.
XAI의 활용가능성
개인적인 사견이 조금 들어가서... 저는 이미지 Domain이 아니면 XAI가 의미가 없다고 생각합니다.
대부분 XAI하면 설명하는게 Convolution Neural Network 기반의 여러 모델들이나 GAN 계열에 대해서 예를듭니다.

그 이유는, 이미지가 변화의 과정을 가장 직관적으로 확인할 수 있기때문입니다.
XAI라고해서 별 색다른 딥러닝 모델이 아닙니다.
기존에 있는 모델의 일부분을 조금 뜯어서 어떻게 변해가는지 hidden layer별로 보거나, GAN에서 z-vector의 값들을 통해 Feature를 구분하는것을 알아내거나, Weight가 어디서 크고 0에 가까운점은 거의 Correlation이 없구나 이런정도 파악할 뿐입니다.
NLP에서도 활용가능성이 있지만, 제가 연구하고 있는 배터리의 실수형 데이터를 Regression을 대체하는 용도로써의 딥러닝에는 하등 의미가없습니다.
Weight와 Bias의 크고작음에 따른 Coefficient확인은 이미 ,Data-preprocessing 단계에서 Input과 Output인자간의 Correlation을 확인하고 학습합니다. 아주 기본적인거죠
즉, 학습하기전에 이미 다 Correlation을 보고 데이터를 선정하는데 굳이 학습시킨후에 XAI로 확인할 필요가 없을뿐더러 시간낭비죠
조금 부정적인것 처럼 적었지만, XAI라는게 전혀 무의미하다는건 아닙니다.
하지만 몇몇 분들이 XAI에 대한 이상한 환상? 이 있어 그부분만은 조금 깨고자 강하게 서두를 정리해보았습니다.
XAI 기법
XAI의 관점은 크게 3가지로 나뉩니다.
1. Complexity
2. Scope
3. Dependency
Complexity
딥러닝은 Black Box이기 때문에 모델 자체가 설명력을 지니지 않는 경우가 대부분입니다.
하지만, 예외적으로 Decision-Tree같은 모델은 모델 그 자체가 설명력을 가지는 경우도 있긴합니다.
(Decision Tree가 대표적 XAI의 예시로 많이 들어지는 이유)

이렇게 모델 자체가 어떤 일부의 설명력을 가질 수 있는 것들을 "Intrinsic" 이라고 합니다.
간단한 선형회귀 모델이나, If-Then Rule, Decision Tree... 처럼 Rule-Based Model에 해당됩니다.
하지만, Layer가 깊어지고 복잡해질수록 모델 그 자체가 설명력을 지니지 않는 경우가 많은데요
이런 경우들은 "Post-hoc(사후처리)"라고 합니다.
모델의 학습이 끝나고 난 후의 결과들을 해석함으로써만 분석이 가능하기 때문이죠
이게 XAI의 가장 큰 한계점입니다. 대부분의 모델에서 Post-hoc을 할수밖에 없습니다.
간단한 모델은 애초에 XAI를 할필요가 없기때문이죠
실제로 XAI를 한다고하는 연구들을 봐도 hidden layer 1,2개? 노드개수도 엄청나게 적게해서 설명가능한인공지능을했다~~ 이런식입니다.
Scope
Scope는 크게 Global하게 보냐, Local하게보냐에 따라 2가지로 나뉩니다.

Local Scope의 대명사이자 ,XAI를 설명할때 가장 많이 사용되는 예시중 하나인 "LIME(Local Interpretable Model-agnostic Explanation"입니다.
컨셉은 간단합니다. 이미지를 여러개 부분 부분 자르고 ,이것들을 학습한 딥러닝의 Input인자로 넣어 각 Class들에 대한 조건부 확률을 보고 분석을 하는것입니다.
즉, 개구리를 예로들면 개구리의 팔, 다리, 눈 각각 이미지들을 잘라서 학습한 딥러닝 모델의 Input 인자로 넣습니다.
그리고 결과를 softmax를 쓰든..해서 확률의 형태로 나오게하고 각각의 잘려진 이미지들이 실제 개구리로 판단하는데 얼마만큼의 기여를 했는지 분석하는게 LIME입니다.
직관적인 결과를 볼 수 있다는 장점이 있지만, 그냥 말이좋아서 XAI이지 노가다입니다.
Dependency
LRP(Layer-wise Relevance Propagation)
이것은 LIME처럼 이미지들을 잘라서 넣는것이 아니라 전체 이미지를 계속 넣되,
학습 Layer의 중간중간을 끊어서 어떤식으로 이미지가 변해가는지 보는것입니다.

De-convoltuion기법으로 확인(2014년 논문)이 가능하지만, Hidden layer간에 연관성을 합리적으로 설명하지 못한다는 한계점이 존재합니다.
또한, 일일이 히트맵(Output이미지들)으로 최종 결과물의 기여도를 판단해야한다는 노가다라는 문제가 있습니다.
이외에, CAM이라고 불리는 연구 계열의 ResNet의 개념을 차용하여 Convolution Layer로 Feature Extracting을하고 Classifier 부분에 pixel값을 Flatten하여 Vector로 Input을 넣는게아니라 GAP(Global Average Pooling)을 하여 이미지의 특성을 그대로 남긴 상태로 GAP의 Weight와 Bias를 보고 분석하는 방식도 있습니다.

결론
XAI는 분명히 연구를 해야하는 분야임에는 맞지만,
현재와 같은식으로 딥러닝을 한 후, 사후분석을 한다고해서 Black Box문제가 해결되는것은 아닙니다.
또한, XAI를 염두에 두어 처음부터 설명가능한 딥러닝을 설계한다고해서 Decision Tree나 간단한 Linear model들만 다루게 되면 굳이 XAI를 할필요가 없습니다.
연구 논문들을 봐도 Hidden layer 1개에 Node 2개짜리를 Weight와 Bias를 분석해서 XAI라고 발표한것들도 있던데요
이런건 하등 의미가없습니다.
XAI는 실수형 데이터를 다루는 제 연구분야보다 이미지 도메인을 다루는데 더욱 적합할것으로 생각됩니다.
왜냐하면, Hidden layer가 지나갈수록 적어도 어떤 변화의 경향성은 볼수있기때문이죠
실수형 데이터 XAI에서 Weight와 Bias를 통해 데이터간의 Correlation을 역으로 알아내는데 사용한다? 어불성설입니다.
데이터 사이언티스트라면 이미 학습하기전에 데이터간 Correlation을 확인하기때문입니다.
따라서, 많은 기사들이나 글들에 적혀있듯, XAI를 활용하면 딥러닝의 모든 난제가 풀리고 블랙박스가 다 해결된다?
전혀 관계가 없고, 연구도 현재 아주 뎌디게 진행되고 있어 아직은 차례가 멀었다라고 할수있습니다.